



The latest entrant into the world of Generative AI, Anthropic’s Claude 3.5 Sonnet is here, and it is already breaking barriers! Developers worldwide have enjoyed Claude 3.5 Sonnet’s amazing capabilities, from coding and debugging several web apps, and instant deployments with the Artifacts feature. Currently, it is proving to be the best LLM for Developers.
However, we must not forget GPT-4o, the super-efficient LLM that has impressed everyone lately with its amazing natural language processing and vision capabilities.
So, it’s time to do a comparison of both these AI models to find out which one is the winner!
Comparing Claude 3.5 Sonnet against GPT-4o
We will compare GPT-4o and Claude 3.5 Sonnet side by side on several tests, and based on the results we will choose the better LLM for each respective task. So, let’s find out!
1) Breadth-First Search with an Interactive Diagram
Our first test for both GPT-4o and Claude 3.5 Sonnet was the Breadth First Search problem. Our task was not just to explain the problem but to also provide an interactive diagram that further explains the problem and helps in better visual learning.
Prompt: “Explain me bfs with a help of interactive diagram”
GPT-4o:
I got almost everything from GPT-4o. It began with providing a good introductory explanation of the Breadth First Search algorithm. Then it also provided an example diagram and a series of diagrams showing how the BFS algorithm works. It also explains theoretically the steps involved in each of the phases of the algorithm.
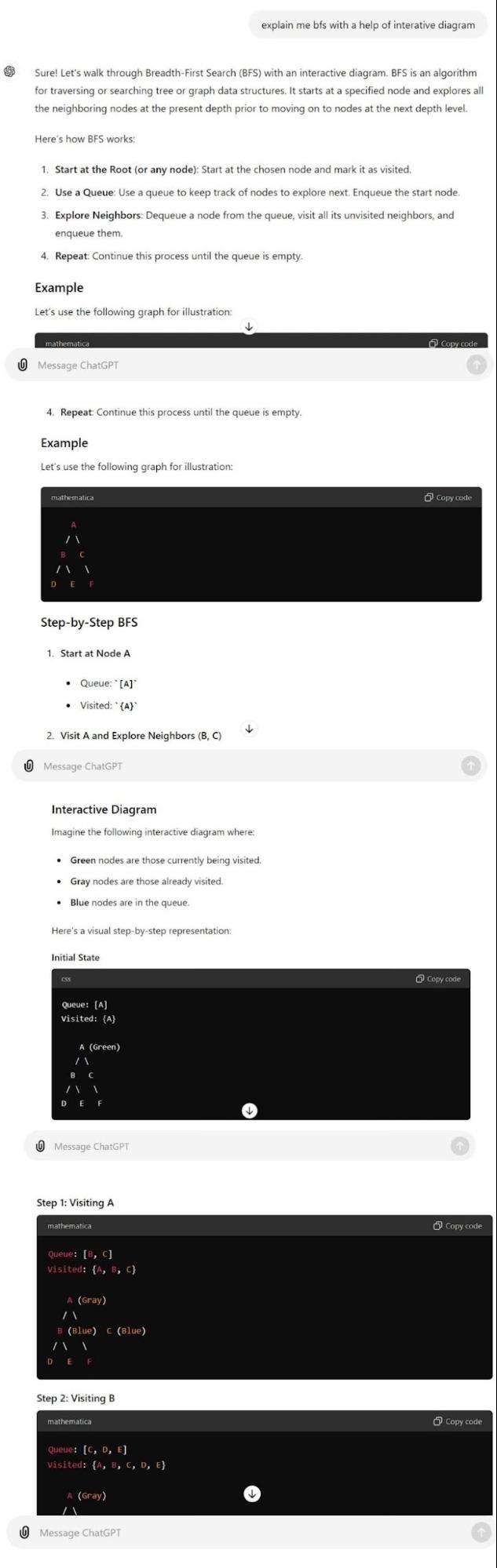
Claude 3.5 Sonnet:
It also explains the algorithm briefly and explains the important steps involved in short. But now let’s take a look at the Interactive Diagram portion in the Artifacts section. The artifacts section is the most powerful portion of the Claude 3.5 Sonnet model. It runs all your codes shows the Web App deployments and even generates several diagrams that you ask for.
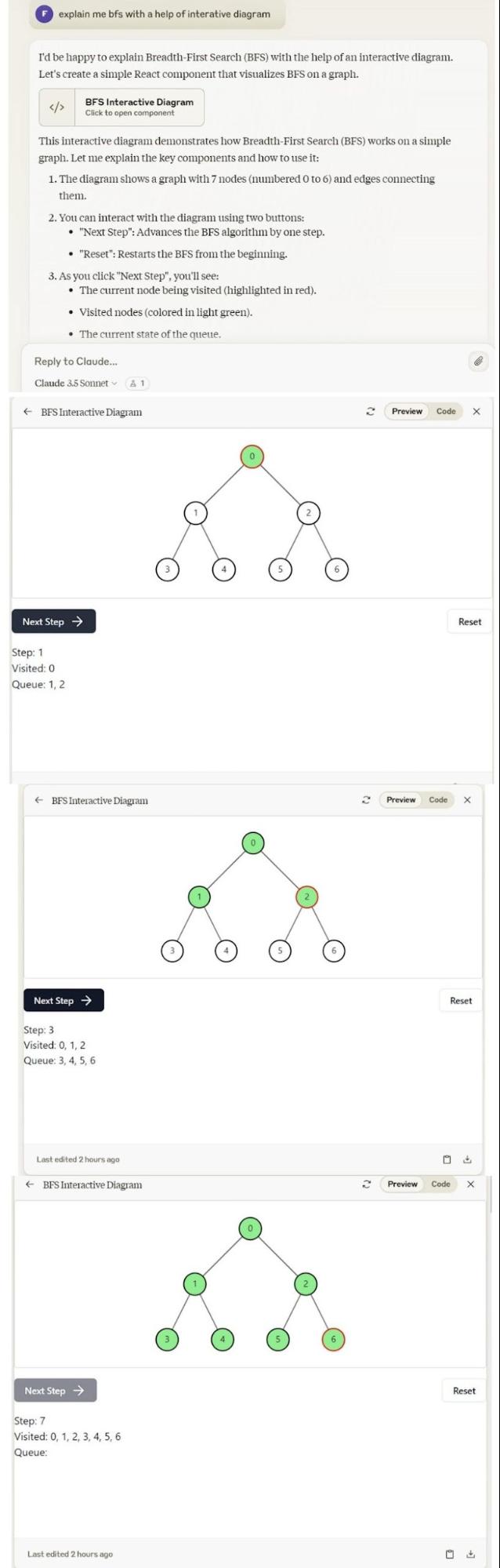
If you look at the Artifacts section here you will notice that the interactive diagram here for BFS is on another level. It comes with a button called ‘Next Step’ which when clicked shows how the algorithm works, with the help of animations. The progressive animations in the BFS Interactive diagram provide a great understanding of the whole algorithm.
The Winner:
The winner here will be Claude 3.5 Sonnet, as the interactive diagram here in the Artifacts section provides a whole new level of learning experience. The step-by-step animated analysis helps in a better understanding of the concept compared to GPT-4o’s model. Although the content may be similar, it is the interactive visual explanation that does the trick for Claude 3.5 Sonnet.
Scores: Claude 3.5 Sonnet – 1, GPT-4o – 0
2) Two Sums Leetcode Problem Test
Our next test was the 2 Sums Leetcode problem test. This time also we needed an interactive diagram from both the models.
Prompt: “Explain 2 sums leetcode problem with the interactive diagram”
GPT-4o:
It provides a well-laid-out and properly explained description of the 2 sums leetcode problem. It does well in providing an example dataset with the hash map approach. It continues to explain the interactive diagram step-by-step again as it did before in the previous problem. Each of the interactive diagrams contains all the data structures in the correct specified order progressively.
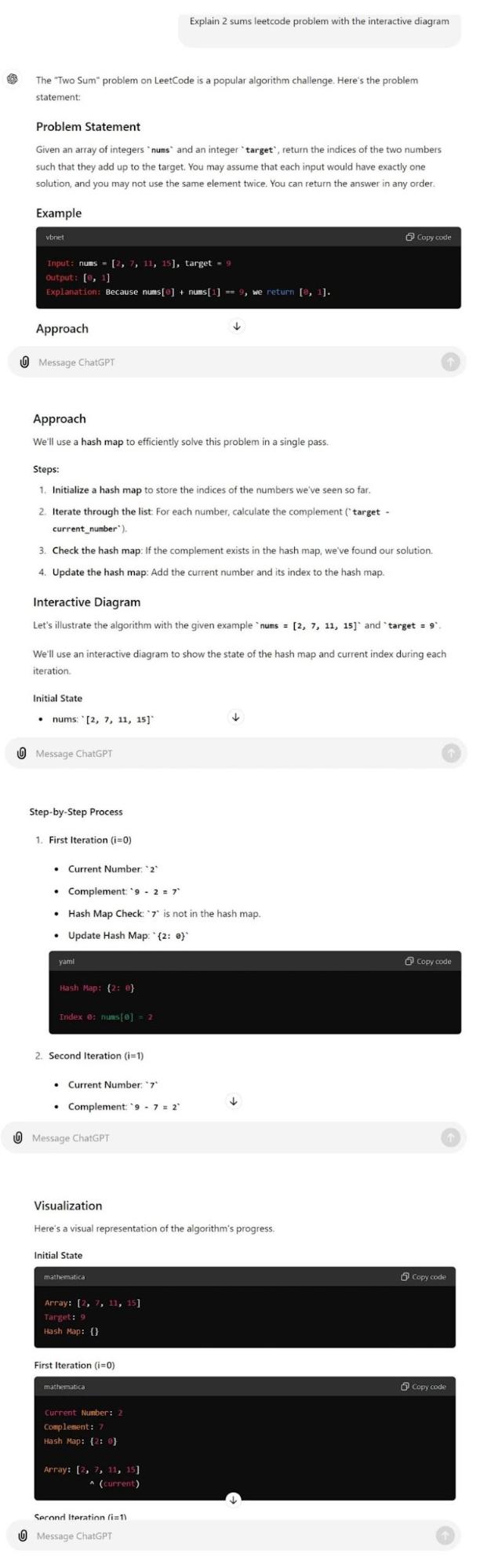
Claude 3.5 Sonnet:
Here the explanation is not as lengthy and informative as GPT-4o’s but it contains the key and relevant points related to the leetcode problem. Now if we look again at the Artifacts portion beside the chat screen of Claude 3.5 Sonnet, the interactive diagram of the 2 sums leetcode problem is very well explained with the help of a step-by-step animation-based progress.
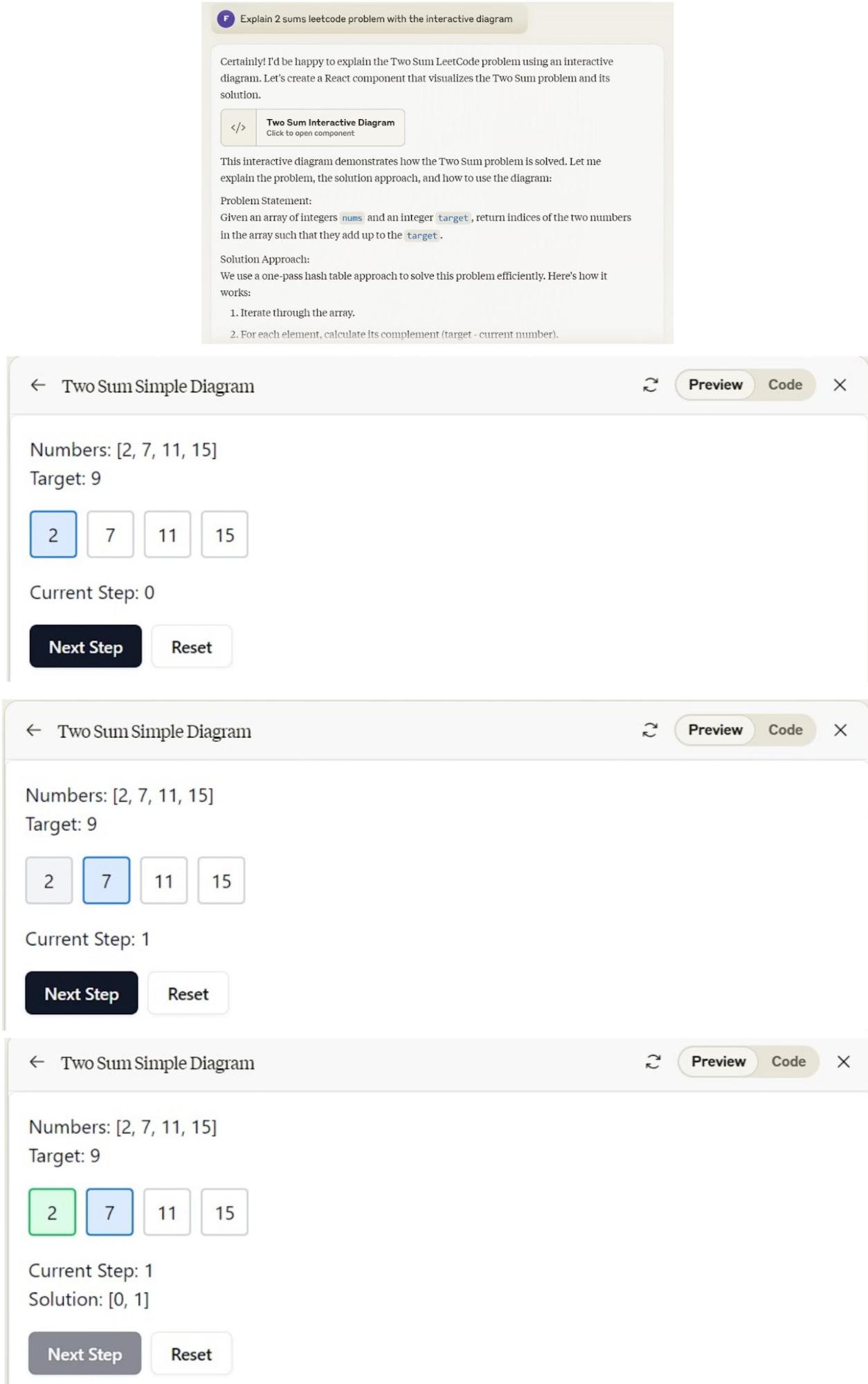
The animation completely explains the problem without the need to even look at the problem explanation!
The Winner:
This time I felt GPT-4o really did well in terms of explaining the code step by step and even providing a sequential series of progressive diagrams explaining the 2 sums leetcode problem workflow. However, still, the winning spot has to go to the Claude 3.5 Sonnet model, because of its unmatched interactive animation-based diagram which explains the problem in one go.
Scores: Claude 3.5 Sonnet – 2, GPT-4o – 0
3) Web Development
The next task was the Web Development task. We asked both GPT-4o and the Claude 3.5 Sonnet model to develop a simple portfolio website with HTML, CSS, and Javascript. We didn’t need any high-quality or highly functional website, we just wanted to see which LLM would do better in producing a better-looking basic website with some innovation.
This is the prompt that we gave to both the GPT-4o and Claude 3.5 Sonnet models.
Prompt: “Write a html, css and javascript code for a portfolio website using bootstrap design. Include functionalities like a menu bar consisting of my details, my education, my socials.”
Both GPT-4o and Claude 3.5 Sonnet responded with the corresponding HTML, CSS, and Javascript files. We ran the files on Visual Studio Code and here are the results we got.
Claude 3.5 Sonnet:
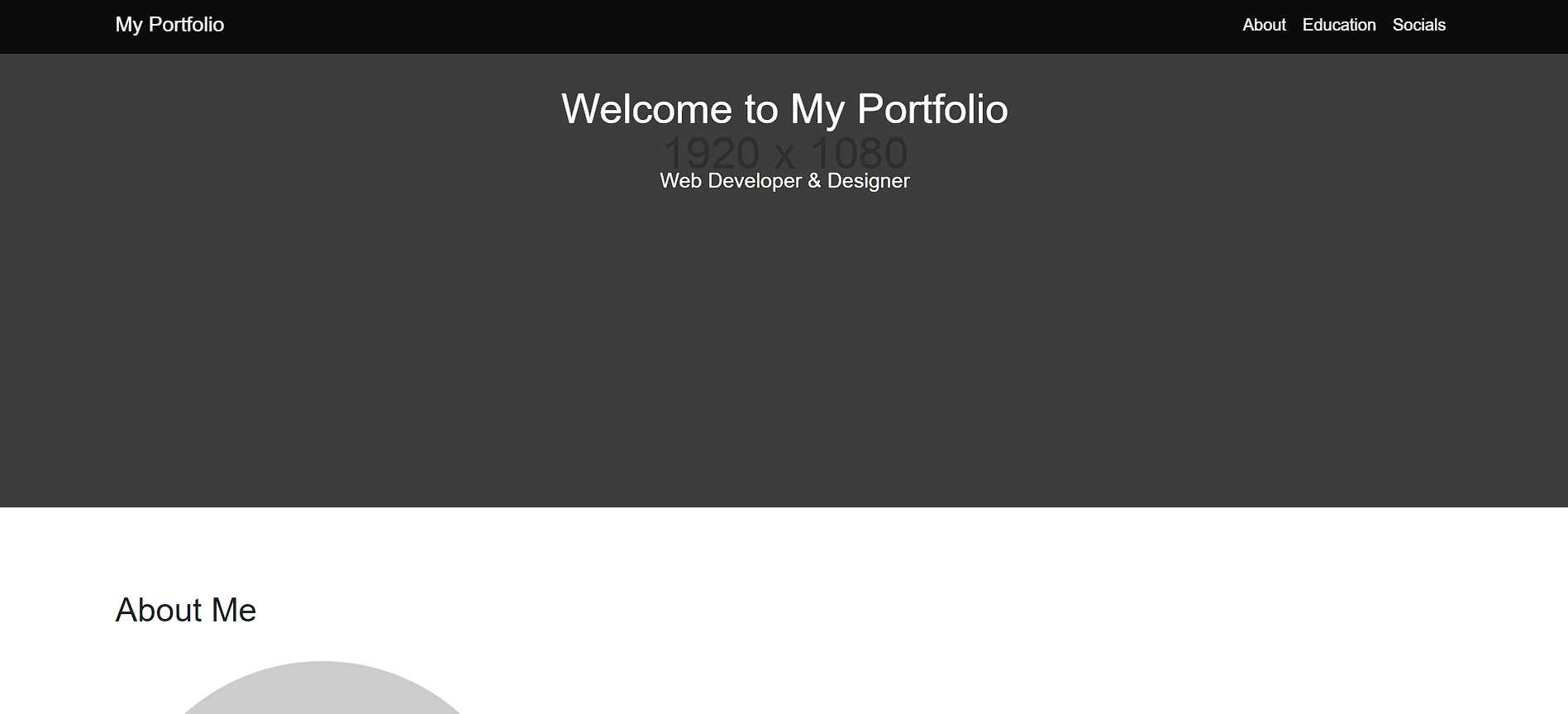
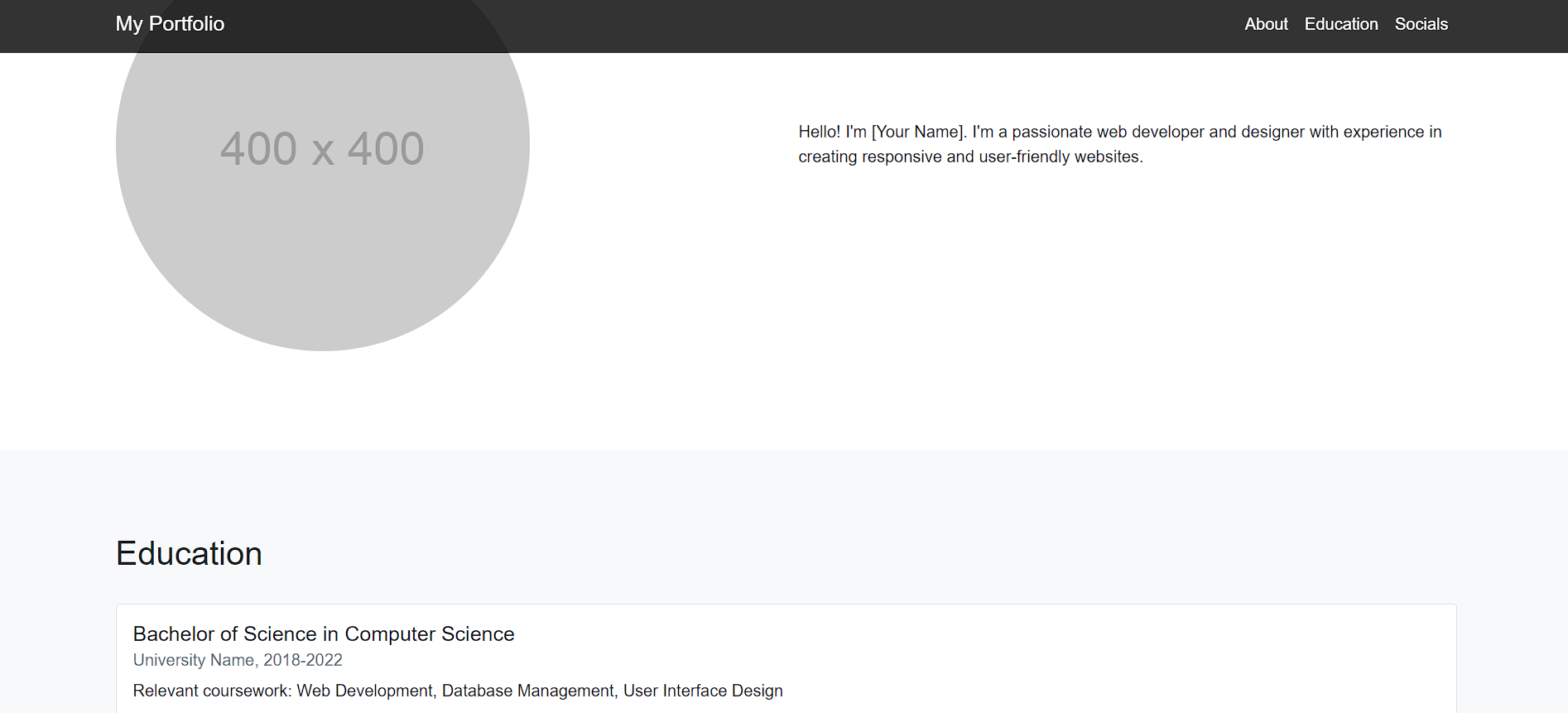
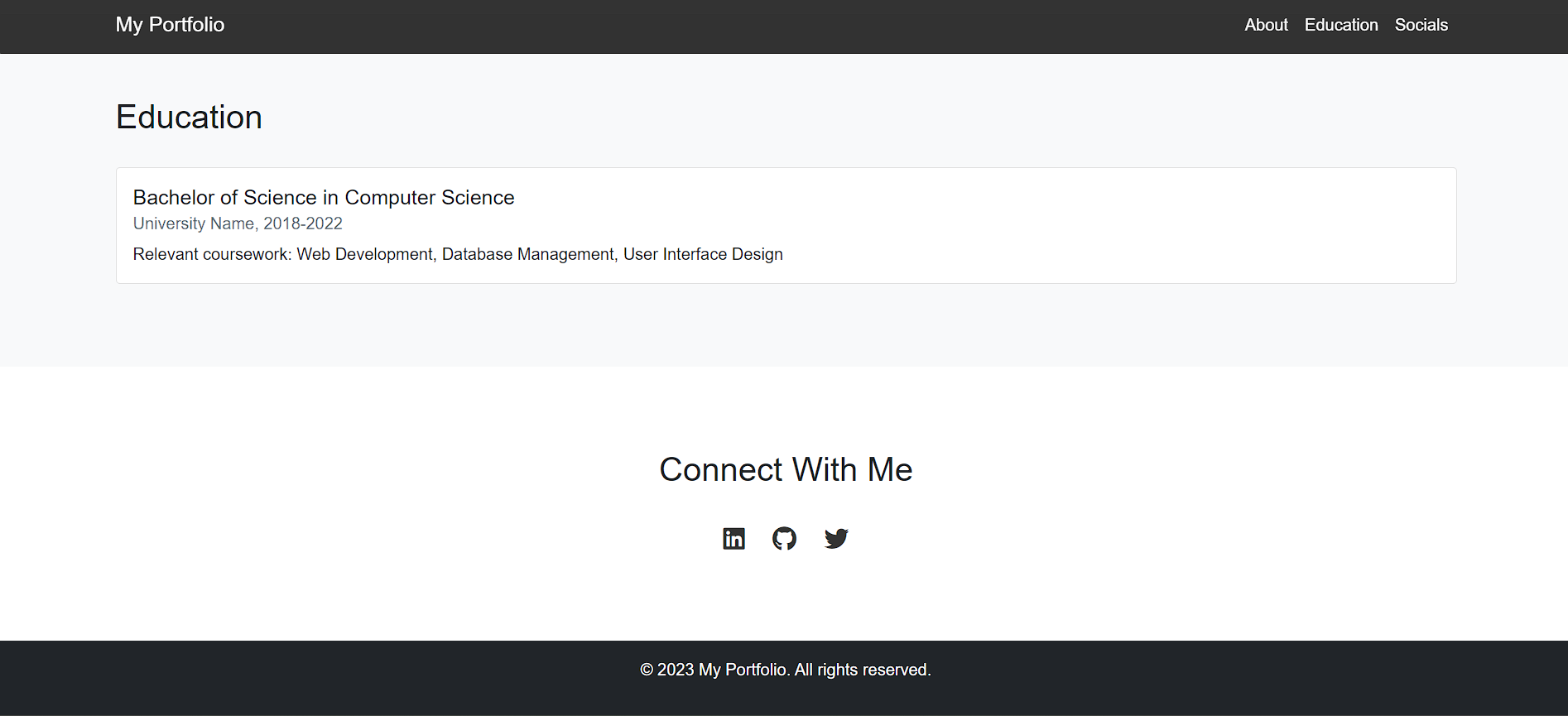
We have split the whole website into 3 different part images to show the full extent and functional capabilities of the website.
GPT-4o:
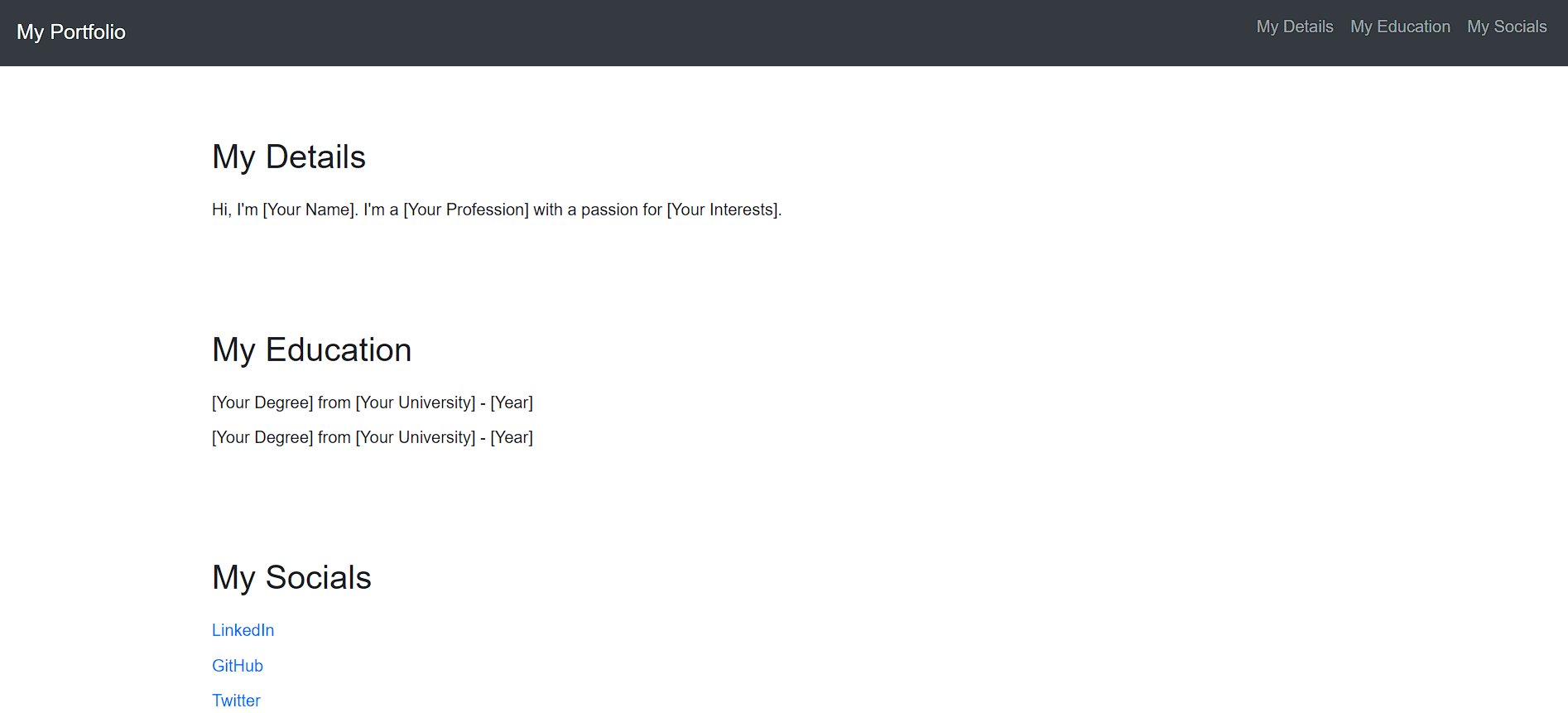
The Winner:
By far the winner here is Claude 3.5 Sonnet. By taking a look at both websites you can easily say that the website produced by Claude looks far more innovative and interesting. There’s a bit more effort into the design and the content.
GPT-4o’s website looks like a simple rough implementation without any creativity at all. However, what impresses me is both the LLMs were smart enough to provide editable sections in the website that a user can tailor according to their details.
Scores: Claude 3.5 Sonnet – 3, GPT-4o – 0
4) Data Analysis
Next up the test we performed was the Data Analysis test. We wanted to see which LLM was better at doing statistical analysis from a huge dataset. So we gave both GPT-4o and Claude 3 Sonnet a dataset of the layoff data of COVID-19 years.
There was a specific numerical column in this dataset called ‘total_laid_off’. We wanted the numerical mean, median, and mode for this column.
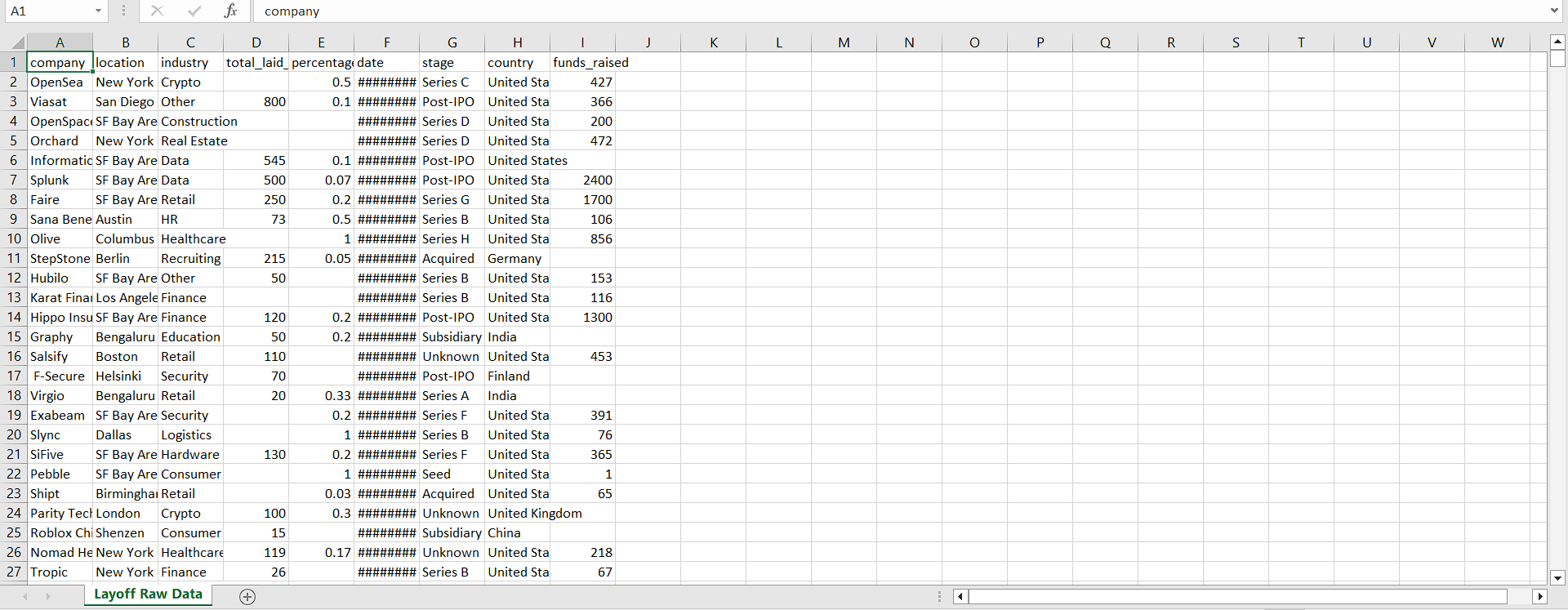
This is the prompt that we gave:
“Based on the layoff dataset, I need you to calculate the mean, median and mode of the dataset. Also, calculate the standard deviation if possible.”
Based on our calculations these are the correct mean, median, and mode of the dataset are 242, 80, and 100 respectively.
Now let’s see how both GPT-4o and Claude 3.5 Sonnet responded.
Claude 3.5 Sonnet:
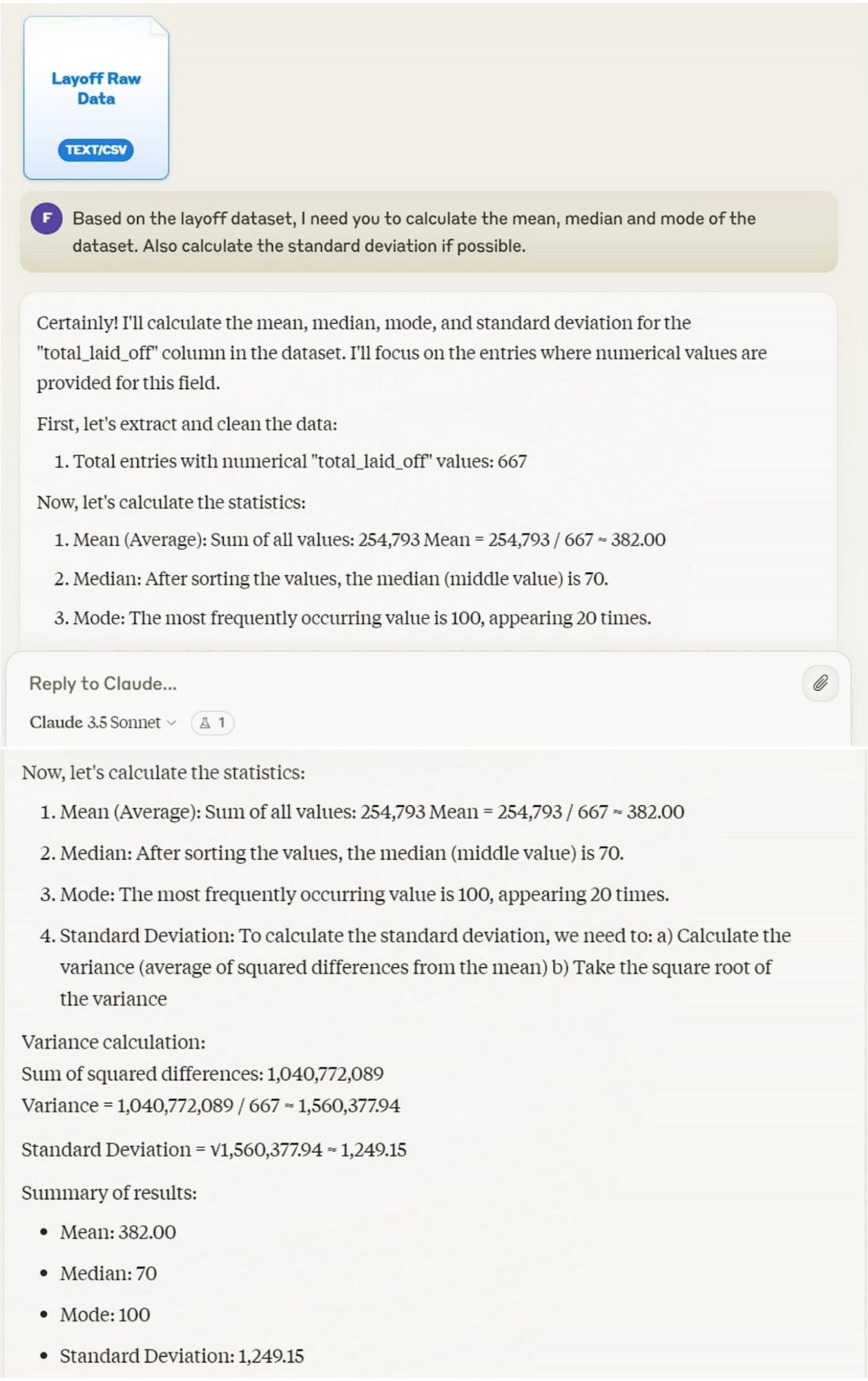
GPT-4o:
To our surprise GPT-4o got every answer right, however, Claude 3.5 messed up its calculations here. Claude 3.5 didn’t get the mean and the median right. Since it got the median wrong, it can be assumed it didn’t rearrange the dataset properly. However, Claude still got the mode value correct.
The Winner:
GPT-4o reigns supreme here by showcasing its excellent statistical data analysis capabilities in this one. It got all three answers correct and showed that it still is better when it comes to Data Analysis on huge datasets.
Scores: Claude 3.5 Sonnet – 3, GPT-4o – 1
5) Tricky Math Problem Test
This time we wanted to see how well both Claude 3.5 Sonnet and GPT-4o do in solving two tricky math problems. Here are both the problems.

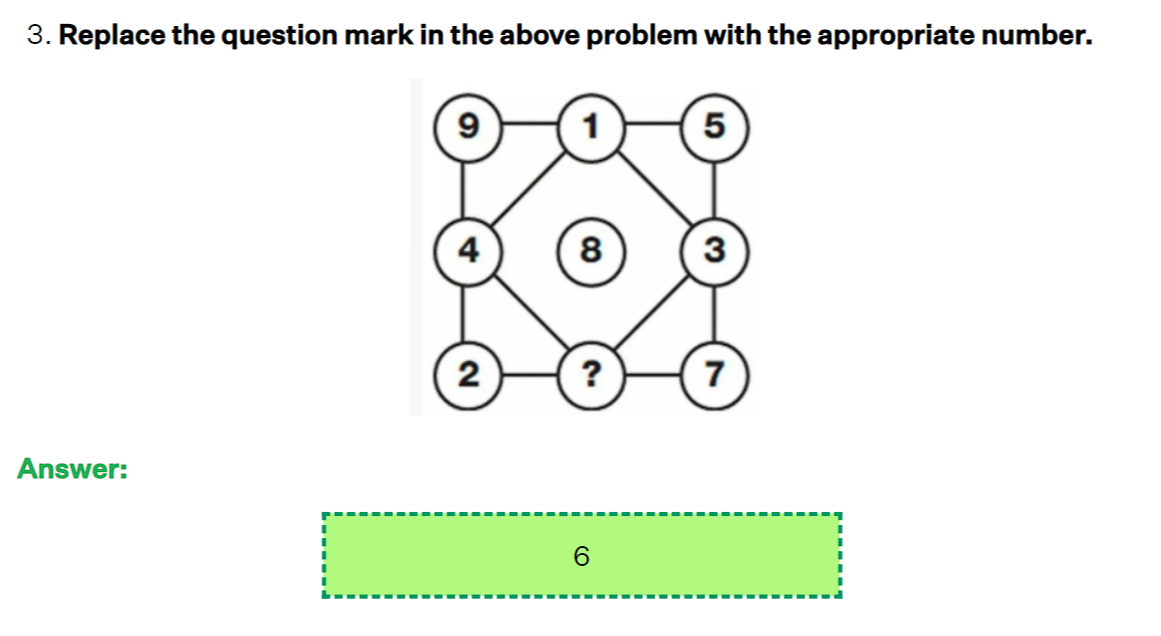
The answers to these questions are 9 and 6 respectively.
This is how both GPT-4o and Claude 3.5 Sonnet responded.
Claude 3.5 Sonnet:

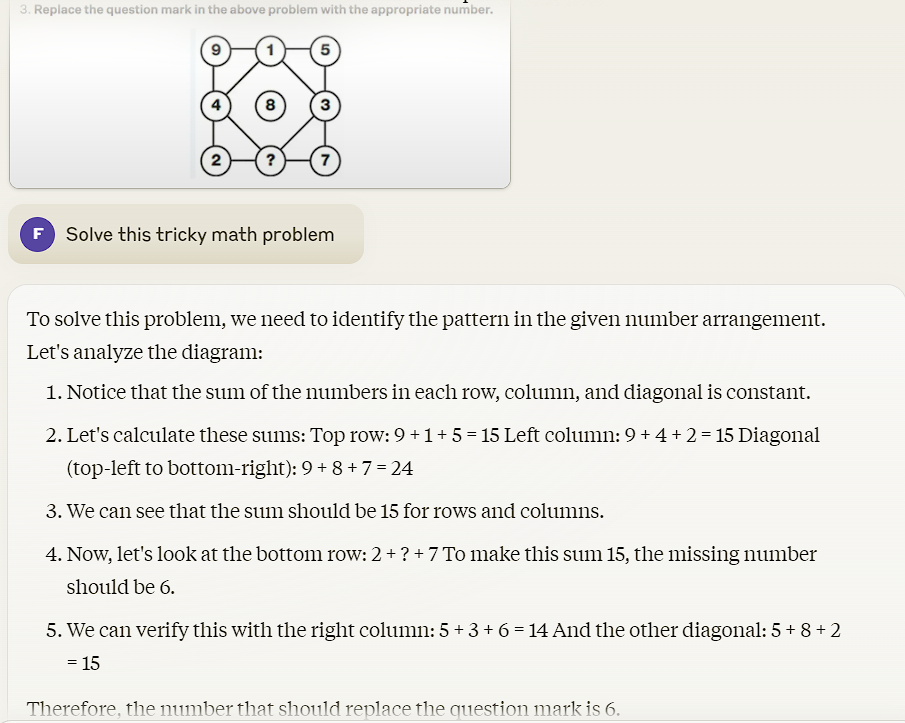
GPT-4o:


The Winner:
You can see both the models got the answers to both the questions right. So, we can assume that both Claude 3.5 Sonnet and GPT-4o are quite powerful when it comes to solving tricky math problems which require deep thinking and lots of analysis. We will call this test a tie.
Scores: Claude 3.5 Sonnet – 4, GPT-4o – 2
Who is the overall Winner?
Claude 3.5 Sonnet has pulled a clean sweep over GPT-4o with an impressive score of 4-2.
When it comes to interactive learning, clearly Claude 3.5 Sonnet is the better model compared to GPT-4o. The artifacts feature in Claude 3.5 Sonnet has completely changed the scene on how AI models show their content to the general audience. I’m beyond amazed at how Claude is deploying amazing web applications side by side instantly.
But when it comes to Data Analysis and reasoning, it is safe to say GPT-4o either outshines or is at par with Claude 3.5 Sonnet. The former did well in the last 2 tests we conducted.
However, we must now divert our attention from the fact that GPT-4o’s Voice Mode which is based on natural language capabilities and smart interactions, is beyond wonders. We have seen what GPT-4o’s Voice Mode is capable of when it comes to real-time communication, training, and other applications.
The tests we conducted were on a limited range of use cases, so they can’t be used to determine a specific ‘better’ model. At the end of the day, as we always say, every AI model is best, depending on what you want to use it for.
Conclusion
Both GPT-4o and Claude 3.5 Sonnet are the top AI models in the current generative AI market. The tremendous technical potential that these two models hold, has already started to revolutionize the world of AI!




