



Google’s DeepMind recently introduced a fresh approach to more comprehensively evaluate text-to-image AI models.
Highlights:
- Google DeepMind introduced an innovative approach called ‘Gecko’ to better evaluate AI systems to convert text into images.
- It introduces a set of 2000 prompts that cover a variety of skills and complexities to find areas where AI models struggle.
- Gecko achieves a notably closer correlation with human judgments compared to previous approaches.
What is the need for Google’s Gecko?
Text-to-image (T2I) models can produce images that don’t align well with the given prompts. Previous research has evaluated the alignment between prompts and generated images by proposing metrics, benchmarks, and templates for collecting human judgments. However, the quality of these components has not been systematically measured.
Gecko addresses this gap by evaluating auto-evaluation metrics and human templates. It includes 3 main aspects:
- A comprehensive skills-based benchmark that can differentiate models across different human templates. This benchmark categorizes prompts into sub-skills, allowing users to identify which skills are challenging and at what level of complexity.
- Human ratings across four templates and four T2I models, totaling over 100,000 annotations. This helps understand where differences arise due to ambiguity in the prompt and where they arise due to differences in metric and model quality.
- A new question-answering-based auto-evaluation metric that is better correlated with human ratings than existing metrics for the new dataset, across different human templates.
The Gecko Framework
The Gecko framework introduces a highly challenging set of 2,000 prompts that cover a wide variety of skills, designed to thoroughly identify specific areas where AI models struggle or falter.
The Gecko2K dataset consists of two subsets designed to comprehensively evaluate text-to-image models across a wide range of skills. The two subsets are referred to as Gecko(R) and Gecko(S). Gecko(R) extends the DSG1K benchmark by using automatic tagging to improve the distribution of skills.
However, it does not consider sub-skills nor cover the full set of skills that are of interest.
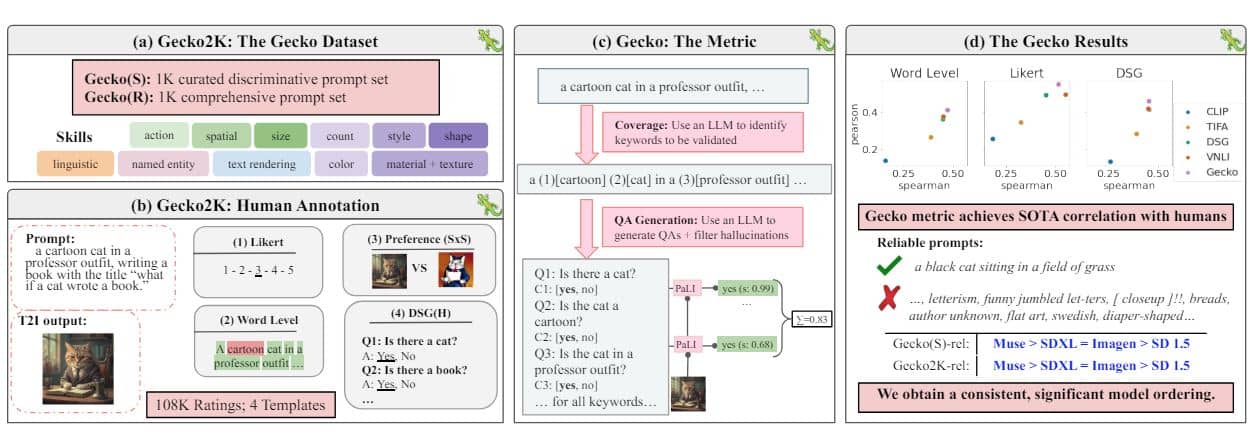
A given prompt in datasets like DSG1K may evaluate many skills, making it difficult to diagnose if a specific skill is challenging or if generating multiple skills is the difficult aspect. To address this, the researchers introduced Gecko(S), a curated skill-based dataset with sub-skills.
The Gecko(S) subset further divides these skills into sub-skills, allowing for a more granular assessment. In curating Gecko2K, the researchers collected human judgments using four distinct templates, resulting in an extensive collection of approximately 108,000 annotations.
To create a fine-grained skill-based benchmark, they ensured good coverage by including prompts for various skills. If many prompts were included for one skill but very few for another, it would fail to highlight a model or metric’s true abilities.
They considered the notion of sub-skills. For a given skill (e.g., counting), they curated a list of sub-skills (e.g., simple modifier: ‘1 cat’ vs additive: ‘1 cat and 3 dogs’). This notion of sub-skills was important, as without this they would be testing only a small part of the distribution and not the entire distribution.
Gecko breaks down these prompts into detailed and granular categories, enabling it to precisely pinpoint not only where models fail, but also the specific levels of complexity at which they start to encounter problems and inaccuracies.
As seen in the image above, the dataset is complemented by the Gecko metric, an innovative evaluation approach that incorporates better coverage for questions, natural language inference filtering, and improved score aggregation techniques.
For evaluating model performance, Gecko introduces a novel question-answering-based metric, one that aligns much more closely with human judgment and perception compared to previous metrics. This new metric highlighted important differences in the strengths and weaknesses of various models that had gone undetected before.
This comprehensive evaluation framework provides valuable insights into the strengths, weaknesses, and areas for improvement across multiple aspects of text-to-image generation and assessment.
Here are the Results
Rigorous testing and evaluation using the comprehensive Gecko framework demonstrated quantitative improvements and superior performance over previous models and evaluation approaches.
Gecko achieved a substantial 12% improvement in correlation with human judgment ratings across multiple templates when compared to the next best metric. Detailed analysis further showed that it was able to detect specific model discrepancies with an 8% higher accuracy in assessing image-text alignment.
In evaluations conducted across the extensive dataset of over 100,000 annotations, it reliably and consistently enhanced the ability to differentiate between models, reducing misalignments and inconsistencies by 5% compared to standard benchmarks.
This shows it’s robust and dependable capability in accurately assessing the true performance of text-to-image generation models.
Gecko achieves a notably closer correlation with human judgments compared to previous approaches and provides valuable, detailed insights into the true capabilities of various models across different skills and complexity levels.
Conclusion
Google DeepMind’s Gecko represents a substantial advancement in evaluating generative AI models. It’s innovative QA-based evaluation metric and comprehensive benchmarking system significantly enhance the accuracy of evaluations for text-to-image models.




