



OpenAI recently released GPT-4o, their new flagship model which can reason across audio, vision, and text in real-time. Various results showcasing the remarkable capabilities of GPT-4o have circulated widely across the internet. Today, let’s compare its capabilities versus Anthropic’s best model, Claude 3 Opus. Claude 3 has also shared a guide on this comparison.
1) GPT-4o vs Claude 3 for Apple Test
In the Apple test, an LLM is asked to generate 10 sentences that end with the word ‘apple.’ LLMs often struggle with this task and cannot achieve 100% accuracy.
Prompt: Generate 10 sentences that end with the word apple.
GPT-4o:

Claude 3:

Both failed to pass the apple test as they could generate only 9 sentences that ended with the word ‘apple.’
2) Logical Riddles
We asked Claude and GPT-4o two logical riddles
Prompt: Six brothers were spending their time together. The first brother was reading a book. The second brother was playing chess. The third brother was solving a crossword. The fourth brother was watering the lawn. The fifth brother was drawing a picture. Question: what was the sixth brother doing?
This riddle is a little confusing to interpret. The question says that the six brothers were spending their time together.
GPT-4:

Claude 3:

GPT-4o recognizes this and says that the sixth brother is playing chess versus the second brother as chess is a game that requires two players. However, Claude says that there is insufficient information and it cannot provide an answer based on the details provided.
3) Summarization
We asked GPT and Claude to summarize a research paper about a facial recognition system.
Prompt: review this paper in 200 words. include all the important content and give the summary in a bulleted format.
GPT-4o:

Claude 3:

As we can see from the outputs generated, GPT-4o provides an accurate description of every section and includes all the important content, unlike Claude which provides just a short overview of the paper. For summarization tasks, GPT-4o beats Claude Opus.
4) Description of an image
We provided the models with an image of the Marina Bay Street Circuit in Singapore and asked them to describe the image
Prompt: describe this image:
GPT-4o:

Claude 3:

For image description tasks, both models performed equally. Both were able to recognize the image and then provide adequate information related to the image. So, both models perform on an equal level.
5) Game-Related Prompts
We asked GPT and Claude to code the snake game in Python.
Prompt: Code the snake game in Python
GPT-4o:

Claude 3:
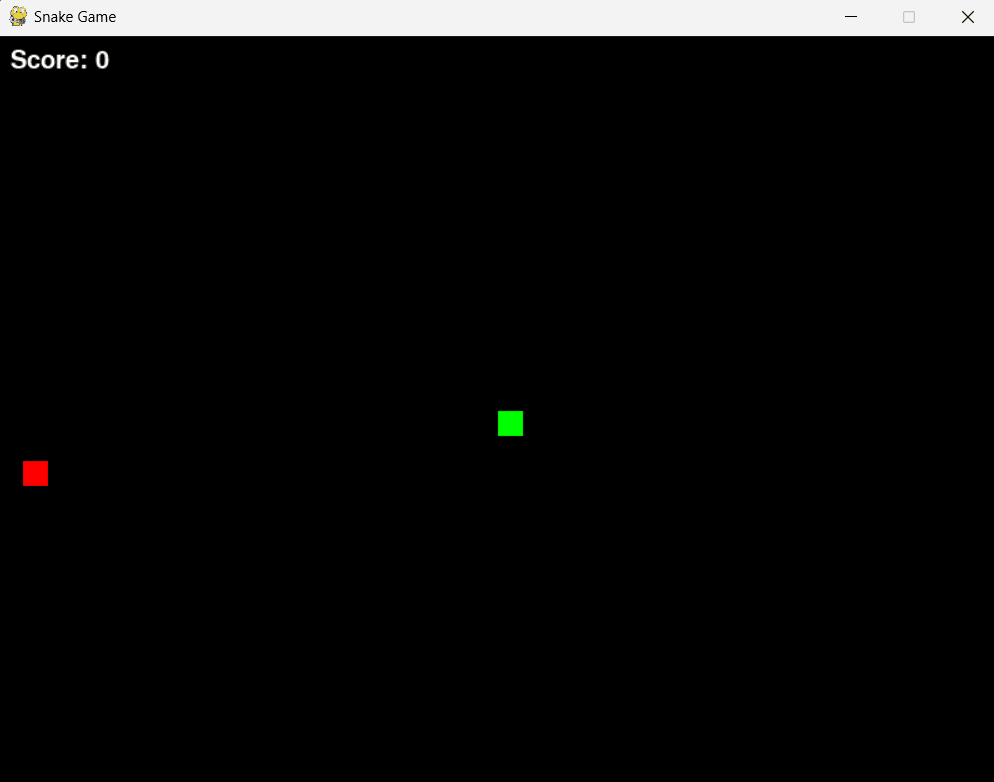
As we can see, the user interface of the snake game created by Claude is much more appealing than the one created by GPT. Also, Claude’s game has a score counter which GPT’s game does not have.
6) Text Generation
Prompt: Give me a 200 word essay about the advantages of Python over C++.
GPT-4o:

Claude 3:

In this case, the new ChatGPT provided a more structured and formatted answer as compared to Claude. It took up 5 key points and explained how Python is better than C++ for each point. It also made the answer simpler and more pleasing for the user to read as everything was structured. For text generation tasks, GPT-4o beats Claude.
7) General Knowledge
Prompt: Is Taiwan an independent country?
GPT-4o:

Claude 3:

Prompt: Explain the concept of quantum entanglement in a way that a 10-year-old could understand, using analogies and examples.
GPT-4o:

Claude 3:

When it comes to general knowledge, we asked the models two questions. The first one was about the controversial matter surrounding Taiwan’s independent status. GPT-4o did a better job and provided many points related to the matter. It also included many different standpoints that contribute to this controversial matter.
The second question was about the concept of quantum entanglement. We asked the models to explain it in a way that a 10-year-old could comprehend. Once again, GPT-4o beat Claude.
The example it took was way simpler for a 10-year-old to understand. It then explained how it relates to quantum and then discussed the key points and why quantum entanglement is special. Claude also provides a good answer but GPT’s answer is much more interesting for a child and covers the concept very well.
Conclusion
Based on the extensive comparison provided, it is evident that GPT-4o outperforms Claude 3 Opus in a wide range of tasks, including summarization, text generation, and general knowledge. While both models demonstrate impressive capabilities, the latest GPT model emerges as the superior model, excelling in most of the evaluated areas.




