



Apple continues to strengthen its AI game. Just a month ago, Apple researchers released its first AI model: ReALM, which dethroned GPT-4 on several reference resolution factors.
But now they have OpenELM, a collection of four very small language models available on Hugging Face. As these models are open-source, developers worldwide can understand how Apple’s AI model would operate on smartphones.
Highlights:
- Apple unveiled OpenELM, a collection of Open-Source Large Language Models (LLMs).
- Comes in a family of 8 models with 4 Pre-trained and 4 Instruction-Tuned models.
- Shows impressive benchmarks across several tasks. Instruction-tuned models show more improvement.
Apple’s OpenELM Models Explained
Apple’s OpenELM is an open-source model family composed of eight very small language models. Out of these eight models four are pre-trained and four are instruction-tuned.
The model weights have been uploaded on HuggingFace where Apple stated that OpenELM stands for “Open-source Efficient Language Models”. When it comes to text-related tasks like writing emails, these models work incredibly well.
Apple is joining the public AI game with 4 new models on the Hugging Face hub! https://t.co/oOefpK37J9
— clem 🤗 (@ClementDelangue) April 24, 2024
The 8 OpenELM Pre-trained and Instruct models come in different sizes of 270 million parameters; 450 million parameters; 1.1 billion parameters; and 3 billion parameters. The number of variables a model can comprehend when making decisions from its training datasets is referred to as its parameters.
Apple has made a smart move in deploying these different model sizes as each smartphone device has different hardware requirements and functionalities.
Recently Microsoft also released Phi-3 a collection of mobile LLMs having an impressive parameter size of 3.8 billion. Google’s Gemma also has a parameter capability of 2 billion. Apple is levelling the competition field with its latest collection of OpenELM models.
How to access OpenELM?
Apple’s Open-Source OpenELM models are available on HuggingFace where developers can access them and install them locally. They can access any pre-trained or instruction-tuned OpenELM model size. For each model, the developer will find different instructions on how to set them up and run them locally.
The OpenELM Architecture
The OpenELM models follow the decoder-only transformer-based architecture. Current LLMs allocate parameters uniformly across layers because they employ the same configuration for every transformer layer in the model.
In contrast to previous models, OpenELM’s transformer layers each have a unique configuration for example, a different number of heads or a different feed-forward network dimension, which leads to a variable number of parameters in each layer of the model.
This enables OpenELM to gain more accuracy by making better use of the parameter budget that is provided. To achieve this uneven distribution of parameters among layers, Apple employs layer-wise scaling, which is also known as block-wise scaling, according to their research paper.
Layer-wise scaling
The feed-forward network (FFN) and multi-head attention (MHA) make up a conventional transformer layer. They modifies the FFN multiplier and the number of attention heads in each transformer layer to account for the non-uniform distribution of parameters in the transformer layer.
Model Training
Apple used CoreNet to train OpenELM variations for 350k iterations, or training steps. AdamW was the optimizer they employed. Additionally, they employed a cosine learning rate schedule, which decayed the ultimate learning rate to 10% of maximal learning after a warm-up of 5,000 iterations. rate.
They employed gradient clipping of 1.0 and weight decay of 0.1. Four OpenELM variations were trained by them (270M, 450M,1.1B, and 3B), and in some cases, they employed activation checkpointing and FSDP.
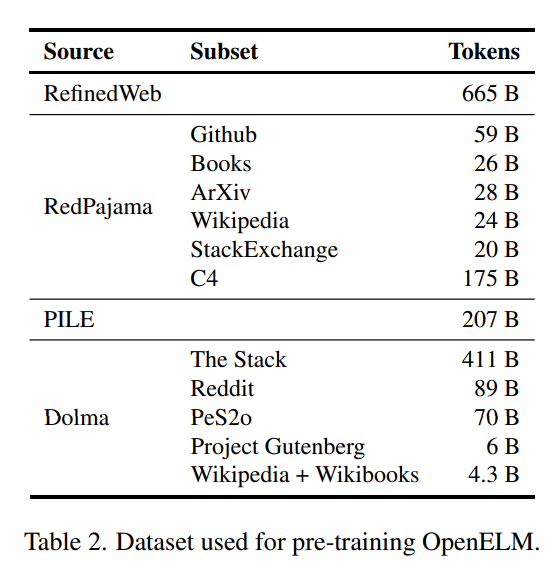
Apple used publicly available datasets for pre-training. RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6 are specifically included in the pre-training dataset, which has roughly 1.8 trillion tokens in total.
Looking at the Benchmarks
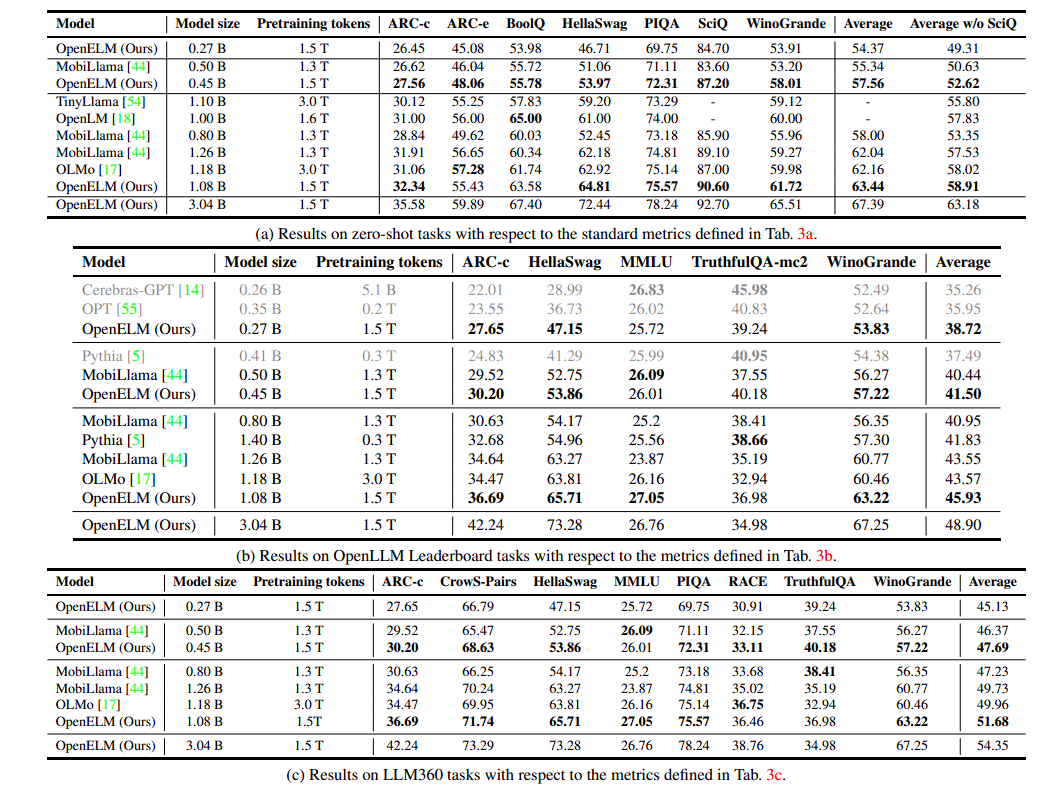
Multiple assessment frameworks were used to test the OpenELM models. The Apple researchers were able to thoroughly assess OpenELM in terms of reasoning (ARC-c, HellaSwag, and PIQA), knowledge understanding (MMLU and RACE), and misinformation & prejudice (TruthfulQA and CrowS-Pairs) thanks to this, which was built on top of LM Evaluation Harness.
They compared OpenELM with publicly available LLMs across these various evaluation frameworks. They chose MobiLlama and OLMo as their baselines because they are pre-trained on public datasets using a similar or larger number of tokens.
The pre-trained OpenELM models showed slight or little improvement in the various benchmarks compared to the MobiLlama and OLMo. The trends are followed by all the different model sizes. This slight improvement was observed in all three tasks namely Zero-Shot, OpenLLM Leaderboard and LLM360.
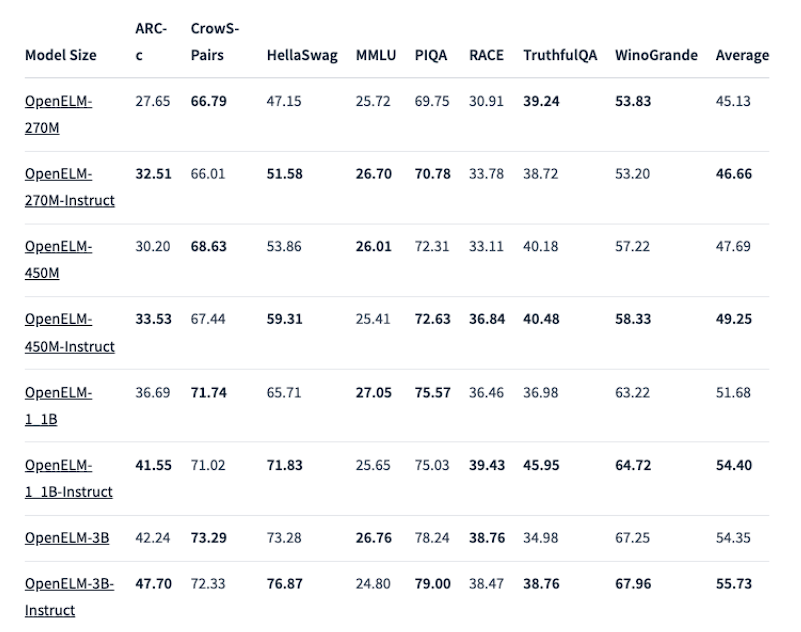
However, the instruction-tuned models showed huge improvements in OpenELM’s accuracy across different model sizes. The score differences between MobiLlama, OLMo, and the OpenELM instruction-tuned models were very high this time.
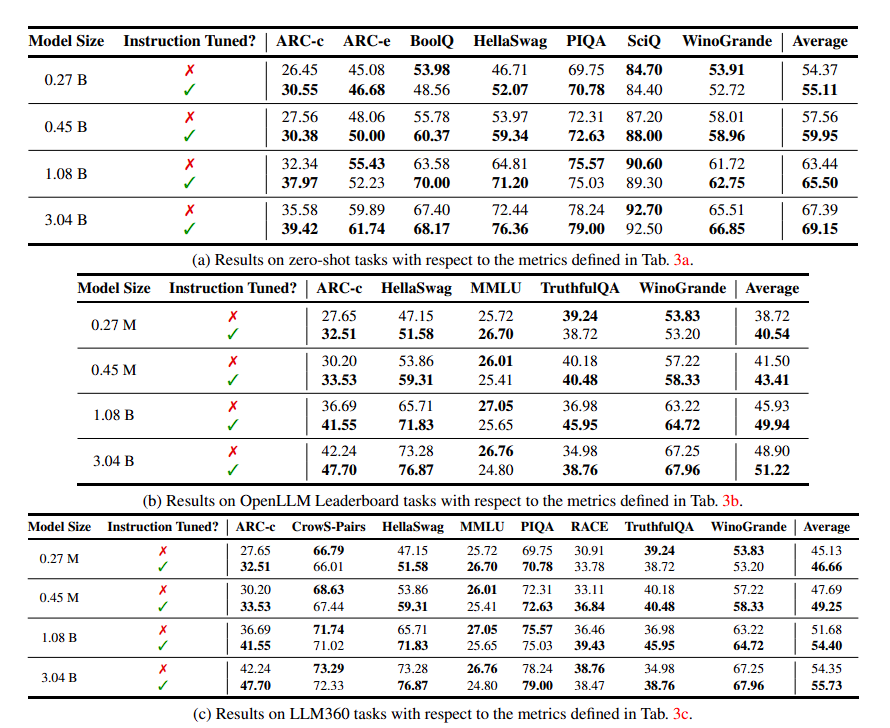
This just shows that the instruction-tuned models are far better compared to the pre-trained models, across several different sizes and benchmarks.
Future AI Updates from Apple
When Tim Cook, the CEO of Apple, stated in February that the business is investing “a tremendous amount of time and effort” in the field, he hinted that generative AI features might be added to Apple products. Apple hasn’t disclosed any details about how it plans to use AI, though.
Apple introduced MLX, a machine learning framework, in December to improve the performance of AI models on Apple Silicon. Additionally, it released the MGIE model of image editing, which enables prompt-based photo correction. There are also rumours that Apple is developing a code completion tool akin to Copilot from GitHub.
Who knows what’s in store for Apple’s AI powerhouse as it recently also reached out to OpenAI and Google to bring their AI features to Apple’s products. Apple’s ReALM also gives us an idea of how powerful its AI model will be.
Conclusion
Apple is finally getting well into the competitive GenAI market with its open-source OpenELM models. These models even though tiny, are highly powerful and can efficiently run on smartphones. Developers can finally get an idea of how Apple’s AI models would run on mobile devices, and how efficiently it can complete several tasks according to its benchmarks.




