



Who thought that one day we would have tiny LLMs that can cope up with highly powerful ones such as Mixtral, Gemma, and GPT? Microsoft Research announced a powerful family of small LLMs called the Phi-3 model family.
Highlights:
- Microsoft unveils Phi-3 model family, a collection of tiny LLMs that are highly powerful and can run on smartphones.
- The model family is composed of 3 models namely Phi-3-mini, Phi-3-small and Phi-3-medium.
- Shows impressive benchmark results and highly rivals models like Mixtral 8x7B and GPT-3.5.
Microsoft’s Phi-3 LLM Family
Microsoft has leveled up its Generative AI game once again. It released Phi-2 back in December 2023, which had 2.7 billion parameters and provided state-of-the-art performance compared to base language models with less than 13 billion parameters.
However many LLMs have been released since then which have outperformed Phi-2 on several benchmarks and evaluation metrics.
This is why Microsoft has released Phi-3, as the latest competitor in the Gen AI market, and the best thing about this model family is that you can run it on your smartphones!
So how powerful and efficient is this state-of-the-art model family? And what are its groundbreaking features? Let’s explore all these topics in-depth through this article.
Microsoft introduced the Model family in the form of three models: Phi-3-mini, Phi-3-small, and Phi-3-medium.
Let’s study all these models separately.
1) Phi-3-mini 3.8b
Phi-3-Mini is a 3.8 billion parameter language model that was trained on 3.3 trillion tokens in a large dataset. It has performance levels comparable to larger versions like Mixtral 8x7B and GPT-3.5, despite its small size.
Because Mini is so powerful, it can operate locally on a mobile device. Because of its modest size, it can be quantized to 4 bits, requiring about 1.8GB of memory. Microsoft used Phi-3-Mini, which runs natively on the iPhone 14 with an A16 Bionic CPU and achieves more than 12 tokens per second while entirely offline, to test the quantized model.

The transformer decoder architecture used in the phi-3-mini model has a default context length of 4K. With a vocabulary size of 320641, phi-3-mini employs the same tokenizer as Llama 2, and it is constructed on a similar block structure.
Thus, any package created for the Llama-2 model family can be immediately converted to phi-3-mini. 32 heads, 32 layers, and 3072 hidden dimensions are used in the model.
The training dataset for Phi-3-Mini, which is an enlarged version of the one used for Phi-2, is what makes it innovative. This dataset includes both synthetic and highly filtered online data. Additionally, the model’s resilience, safety, and chat structure have all been optimized.
2) Phi-3-Small and Phi-3-Medium
Additionally, Phi-3-Small and Phi-3-Medium versions from Microsoft have been released; these are both noticeably more powerful than Phi-3-Mini. Using the tiktoken tokenizer, Phi-3-Small, with its 7 billion parameters, achieves better multilingual tokenization. It has an impressive 100,352-word vocabulary and an 8K default context.
The Phi-3-small model has 32 layers and a hidden size of 4096, following the typical decoder design of a 7B model class. Phi-3-Small uses a grouped-query attention system, where four queries share a single key, to reduce the KV cache footprint.
Additionally, phi-3-small maintains lengthy context retrieval speed while further optimizing KV cache savings with the usage of new block sparse attention and alternate layers of dense attention. For this model, an extra 10% of multilingual data was also used.
Using the same tokenizer and architecture as phi-3-mini, Microsoft researchers also trained phi-3-medium, a model with 14B parameters, on the same data for a slightly longer number of epochs (4.8T tokens overall as compared to phi-3-small). The model has an embedding dimension of 5120 and 40 heads and 40 layers.
Looking At the Benchmarks
The typical open-source benchmarks testing the model’s reasoning capacity (both common sense reasoning and logical reasoning) were used to test the phi-3-mini, phi-3-small, and phi-3-medium versions. They are contrasted with GPT-3.5, phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, and Llama-3-instruct8b.
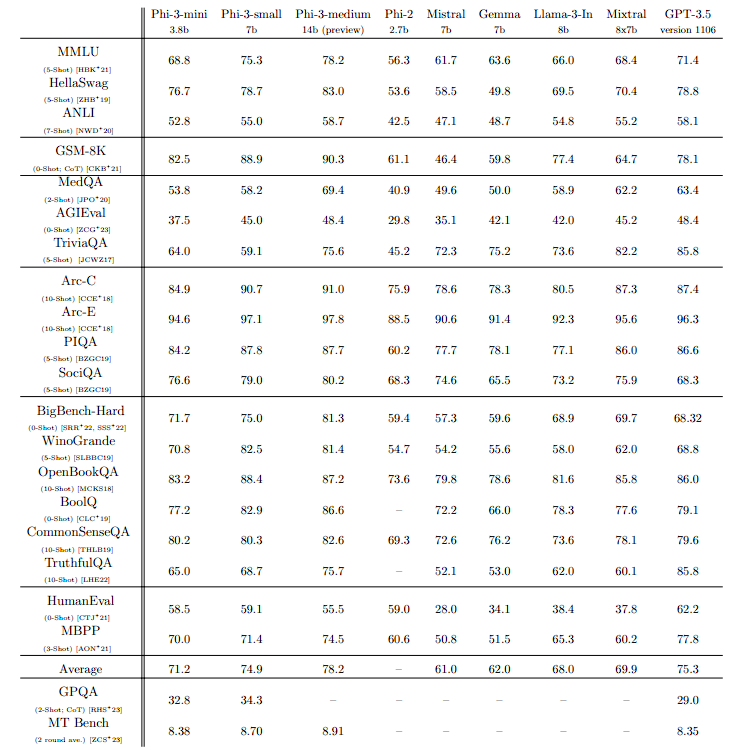
Phi-3-Mini is suited for mobile phone deployment, scoring 69% on the MMLU test and 8.38 on the MT bench.
With an MMLU score of 75.3, the Phi-3-small 7 billion parameter model performs better than Meta’s newly released Llama 3 8B Instruction, which has a score of 66.
However, the biggest difference was observed when Phi-3-medium was compared to all the models. It defeated several models including Mixtral 8x7B, GPT-3.5, and even Meta’s newly launched Llama 3 on several benchmark metrics such as MMLU, HellaSwag, ARC-C, and Big-Bench Hard. The differences were huge where Phi-3-medium highly outperformed all the competitors.
This just goes to show how powerful these tiny mobile LLMs are compared to all these large language models which need powerful GPUs and CPUs to operate. The benchmarks give us an idea that the Phi-3 model family will do quite well in coding-related tasks, common sense reasoning tasks, and general knowledge capabilities.
Are there any Limitations?
Even though it is too powerful for its size and deployment device, the Phi-3 model family has one major limitation. Its size essentially limits it for some tasks, even if it shows a comparable level of language understanding and reasoning capacity to much larger models. For instance, its inability to store large amounts of factual knowledge causes it to perform worse on tests like TriviaQA.
“Exploring multilingual capabilities for Small Language Models is an important next step, with some initial promising results on phi-3-small by including more multilingual data. The use of carefully curated training data, targeted post-training, and improvements from red-teaming insights significantly mitigates these issues across all dimensions. However, there is significant work ahead to fully address these challenges.”
Microsoft also provided a potential solution to this drawback. It thinks a search engine added to the model can help with these flaws. Furthermore, the model’s limited language proficiency in English emphasizes the necessity of investigating multilingual capabilities for Small Language Models.
Is Phi-3 Safe?
The responsible AI guidelines of Microsoft were followed in the development of Phi-3-mini.
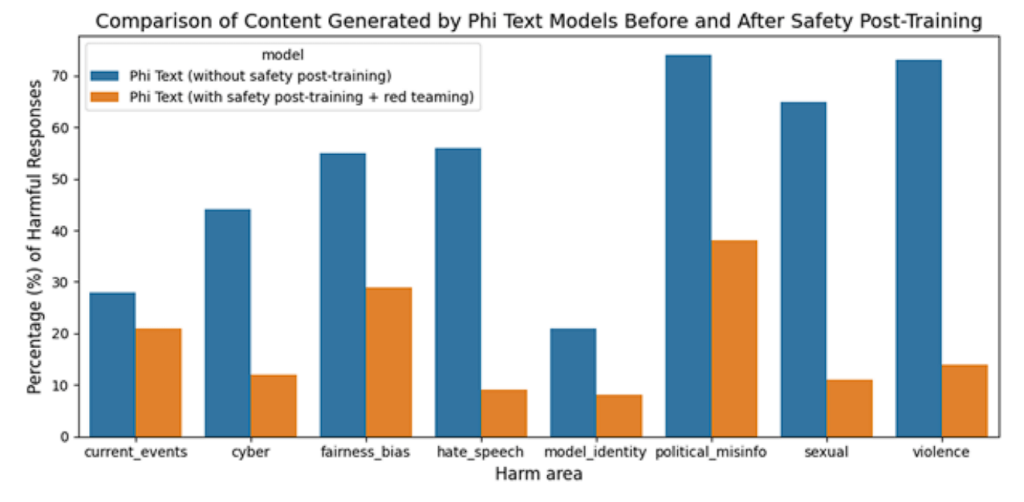
The total strategy included automated testing, evaluations across hundreds of RAI harm categories, red-teaming, and safety alignment in post-training. Several in-house created datasets and datasets with adjustments influenced by helpfulness and harmlessness preferences were used to address the RAI harm categories in safety post-training.
To find further areas for improvement during the post-training phase, a Microsoft independent red team conducted an iterative analysis of phi-3-mini. Microsoft refined the post-training dataset by selecting new datasets that addressed their insights, as a result of receiving input from them. The procedure significantly reduced the rates of adverse responses.
Conclusion
Are we on the verge of a new era for Mobile LLMs? Phi-3 is here to answer this question. The mobile developer community will be highly benefit from Phi-3 models, especially Small and Medium. Recently, Microsoft has also working on the VASA-1 image to video Model, which is also a big thing in the gen AI space.




