



Meta AI recently released Llama 3, the company’s latest cutting-edge open-source LLM. The model has sent shockwaves all over the internet because of its remarkable capabilities. Meta claims that Llama 3 can beat several existing LLMs on key benchmarks, igniting discussions and anticipation within the tech community.
Llama 3 has been hosted on various platforms and is easily accessible. Let us compare Meta’s Llama 3 with Anthropic’s latest and best model, Claude 3 Opus. Here are a few comparisons.
1) Llama 3 vs Claude 3 Opus: Apple Test
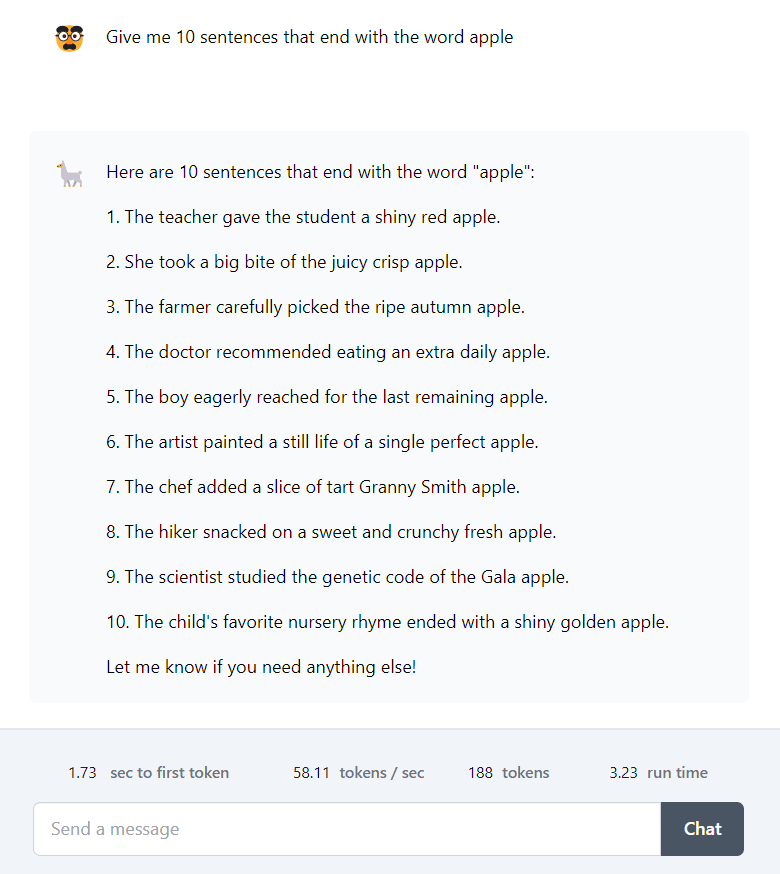
In the Apple test, an LLM is asked to generate 10 sentences that end with the word ‘apple.’ LLMs often struggle with this task and cannot achieve 100% accuracy. We performed the Apple Test on Llama 3 and Claude 3 Opus.
Llama 3:
Claude 3 Opus:

To everyone’s surprise, Llama 3 achieved 100% accuracy by generating 10 sentences that end with Apple. However, Claude 3 Opus could generate only 8 such sentences thus achieving an accuracy of 80%. So, for the Apple Test, Llama 3 convincingly beats Claude Opus.
2) Mathematical Logic Puzzles
We tested both models on a couple of mathematical puzzles.
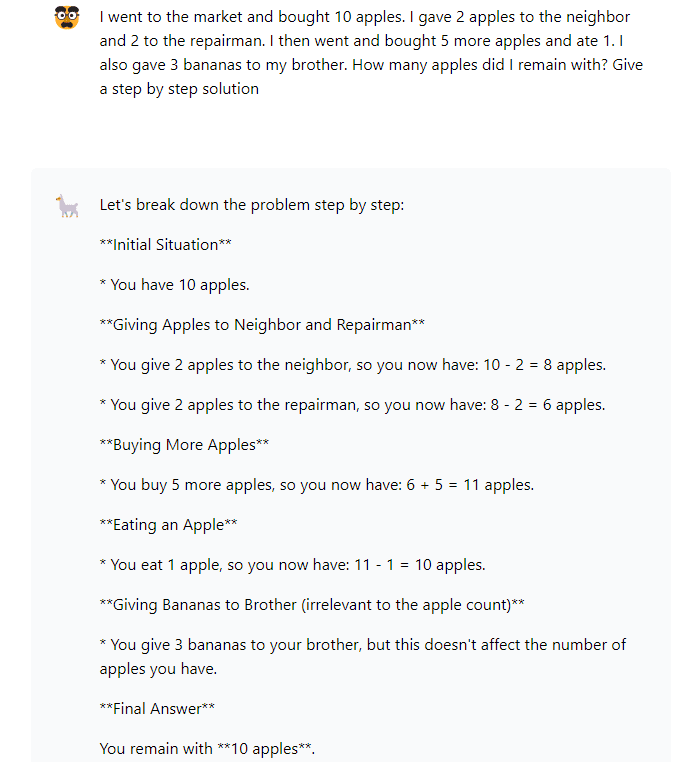
The first puzzle was as follows: “I went to the market and bought 10 apples. I gave 2 apples to the neighbour and 2 to the repairman. I then went and bought 5 more apples and ate 1. I also gave 3 bananas to my brother. How many apples did I remain with?”.
The catch in this puzzle is ‘I also gave 3 bananas to my brother.’ LLMs often get confused due to this statement and give wrong answers. The correct answer to this question is 10.
Llama 3:
Claude 3:

Both were able to answer this correctly with a step-by-step solution.
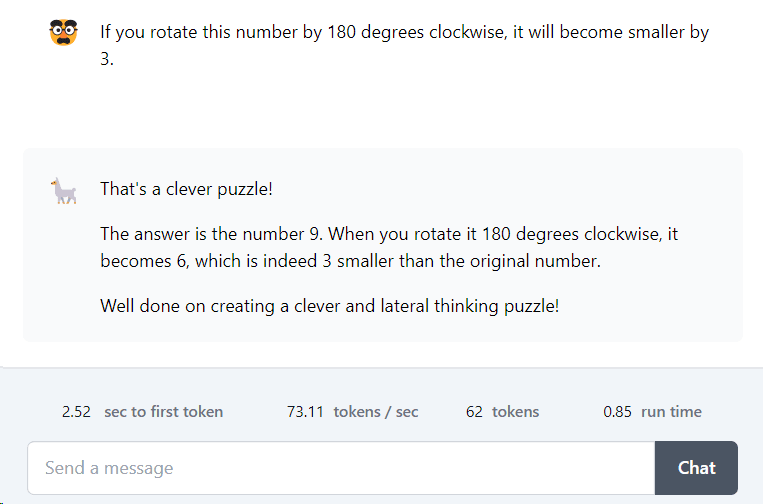
Now, Let’s look at the second puzzle. The second puzzle is: “If you rotate this number by 180 degrees clockwise, it will become smaller by 3.”
Here, the LLM should be able to understand the meaning of clockwise and anti-clockwise rotation and thus give the correct number based on that. The correct answer is 9.
Llama 3:
Claude 3:

Unlike the first puzzle, in this case, only Llama gave the correct answer. It also gave the correct explanation by stating that rotating 9 clockwise by 180 degrees gives 6 which is 3 smaller.
Claude Opus gave 6 as the wrong answer. This is because when you rotate 6 clockwise by 180 degrees, you get 9 which is bigger by 3. Thus, in mathematical puzzles, we can say that Llama 3 beats Claude Opus.
3) Code Generation and Debugging
Now, let’s consider a few coding-related examples.
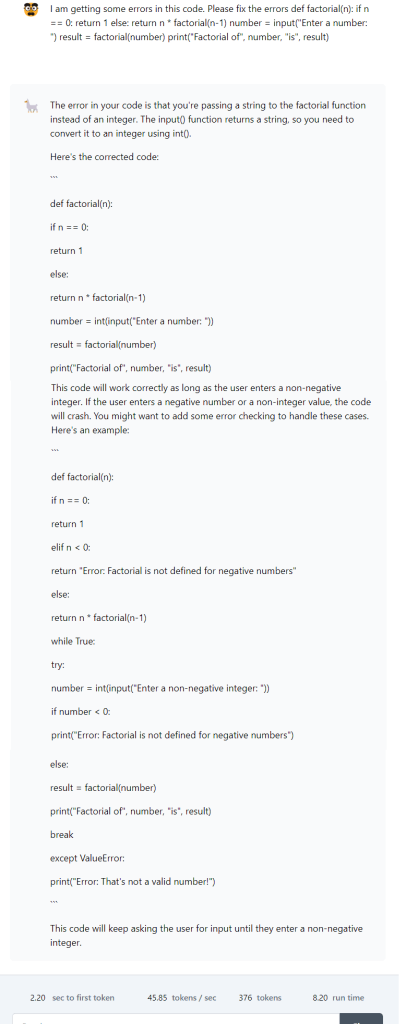
In the first example, we provided the models with a code that had a few errors and asked the models to debug and correct the code. The code was to calculate the factorial of a number.
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
number = input("Enter a number: ")
result = factorial(number)
print("Factorial of", number, "is", result)
In this code, there were a couple of errors. The basic error was that the input was in the form of a string which had to be changed to an integer. Secondly, if the user entered a non-negative number or a non-integer value, the code would crash as it had no error handling. Let’s see how the models performed.
Llama was able to fix both these errors and provided the new code with appropriate changes. It also explained where the errors were and why they needed to be fixed. This is impressive as it helps the user understand mistakes simply.
On the other hand, Claude 3 Opus was able to identify and fix only one error which was related to the input type. It didn’t identify the second error regarding error handling and input validation.
Llama 3:
Claude 3:
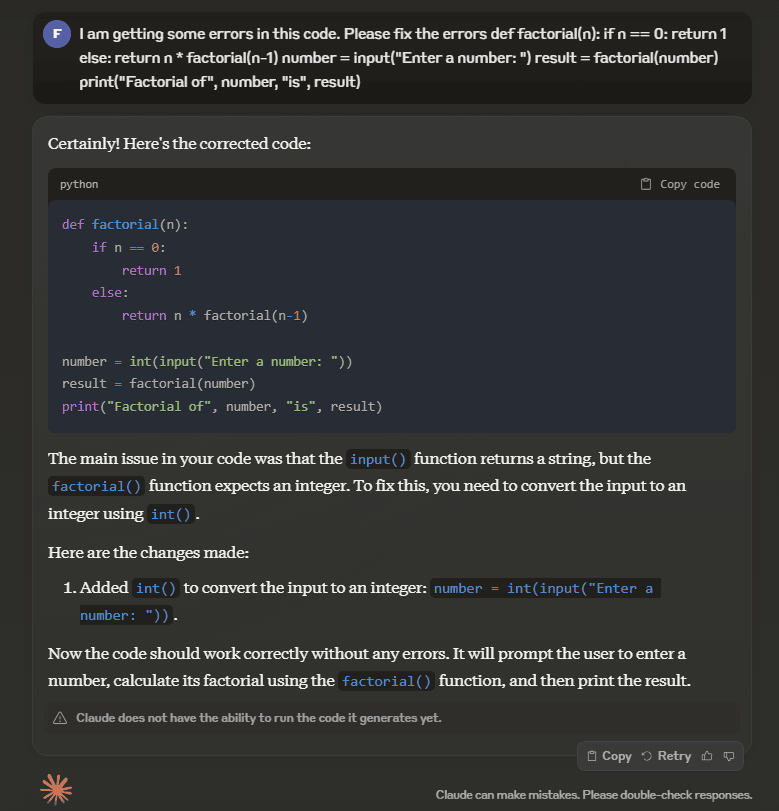
So, in this case, Llama 3 outperformed Claude 3 Opus.
In the second example, we asked the models to write a Python function to find the nth number in the Fibonacci Sequence.
In this case, both the models gave similar codes along with correct explanations. They also stated that the algorithm would have to be changed for larger numbers because it would affect the time complexity.
Llama 3:

Claude 3:
Upon evaluation of both examples, we can say that Llama 3 edges Claude 3 Opus in terms of coding.
4) General Knowledge
We tested both models on general knowledge questions. We asked the models why the sun sets in the west.
Llama 3:

Claude 3:

Both models provided an accurate explanation for this question.
5) Text Generation, Summarization, and Translation
For text generation, we asked the models to write a 300-word article about the advantages of Python over Javascript.
Llama 3:

Claude 3:

Both models made excellent articles with various points in favour of Python along with the required reasons. However, Claude’s article edges out Llama’s as it is more informative and discusses various extra points.
We also asked the models to summarize an article about the concept of ‘Real Numbers.’
Llama 3:

Claude 3:

For summarization tasks, Claude 3 Opus outperforms Llama 3 as it gives summaries with more information and preserves important context from the original text. It can also summarize documents such as PDFs and Word Files unlike Llama 3.
For text generation and summarization tasks, Claude 3 Opus outperforms Llama 3.
When it comes to text translation, we provided the models with an English sentence was asked them to translate it to French. We also told the models to take their liberties so that the translated sentence sounds nice.
Llama 3:

Claude 3:

The models gave similar translations. However, Llama stood out over Claude as it also suggested additional translation to make the sentence sound more lyrical and evocative in French.
In terms of text translation, Llama 3 beats Claude 3 Opus.
Conclusion
Meta’s open-source model Llama 3 represents a significant step forward in today’s ever-evolving LLM landscape. While Llama demonstrates superior performance in certain tasks such as mathematical puzzles and code generation, Opus excels in general knowledge questions and text summarization.




