



Reka Core outperforms Claude 3 Opus, Gemini Ultra, and GPT-4 on various benchmarks for video and text understanding. So, how powerful is the Reka Core? What are its groundbreaking features? Let’s get right into it!
Highlights:
- Reka announces Reka Core, its latest addition to its family of multimodal language models.
- Comes with several features such as a 128K Context Window, Multilingual Capabilities and Reasoning.
- Available for use in API Access and Reka Playground.
Reka Core Multimodal Language Model Explained
San Francisco-based AI startup Reka, founded by researchers from Google DeepMind and Meta, introduced their latest multimodal language model called Reka Core.
Meet Reka Core, our best and most capable multimodal language model yet. 🔮
— Reka (@RekaAILabs) April 15, 2024
It’s been a busy few months training this model and we are glad to finally ship it! 💪
Core has a lot of capabilities, and one of them is understanding video — let’s see what Core thinks of the 3 body… pic.twitter.com/5ESvog35e9
For the past few months Anthropic’s Claude 3 model family, Google’s Gemini 1.5 Pro, and Open AI’s GPT-4 Turbo Vision have made quite an impact on the Gen AI market. And now we have another competitor in the field courtesy of Reka.
Reka Core is the latest addition to Reka’s family of leading multimodal models. It is described as the “largest and most capable model” offered by the company, and thousands of GPUs are used in its training process.
“We introduce Reka Core, Flash, and Edge, a series of powerful multimodal language models trained from scratch by Reka. Reka models are able to process and reason with text, images, video, and audio inputs”
Reka Edge and Flash are the other models in the family having parameter sizes of 7B and 21B respectively. They are state-of-the-art models based on their compute class and are also described as ‘dense models’.
However, the latest family member, Reka Core is a highly powerful language model. Core approaches today’s leading frontier models such as OpenAI’s GPT-4, Anthropic’s Claude 3 Opus, and Google’s Gemini 1.5 Pro on both automatic evaluations and blind human evaluations.
Core offers exceptional value considering its size and capabilities when considering the overall cost of ownership. Largely new use cases are made possible by the combination of Core’s capabilities and deployment flexibility.
How Can You Access It?
Reka Core is available today via API, on-premise, or on-device deployment options. Click here to get redirected to Reka Playground where you will have access to Reka Edge, Flash, and Core models. All you have to do is log in or set up a Reka Account and you are good to go to have conversations with Reka Core.
Looking at the Benchmarks
Reka Core has highly competitive benchmarks across several metrics compared to GPT-4, Claude 3 Opus, and Gemini 1.5 Pro.
Core performs similarly to GPT-4V on MMMU, beats Claude-3 Opus on Reka’s multimodal human assessment carried out by an impartial third party, and beats Gemini Ultra on video tasks. When it comes to language tasks, Core performs comparably to other frontier models using reliable benchmarks.
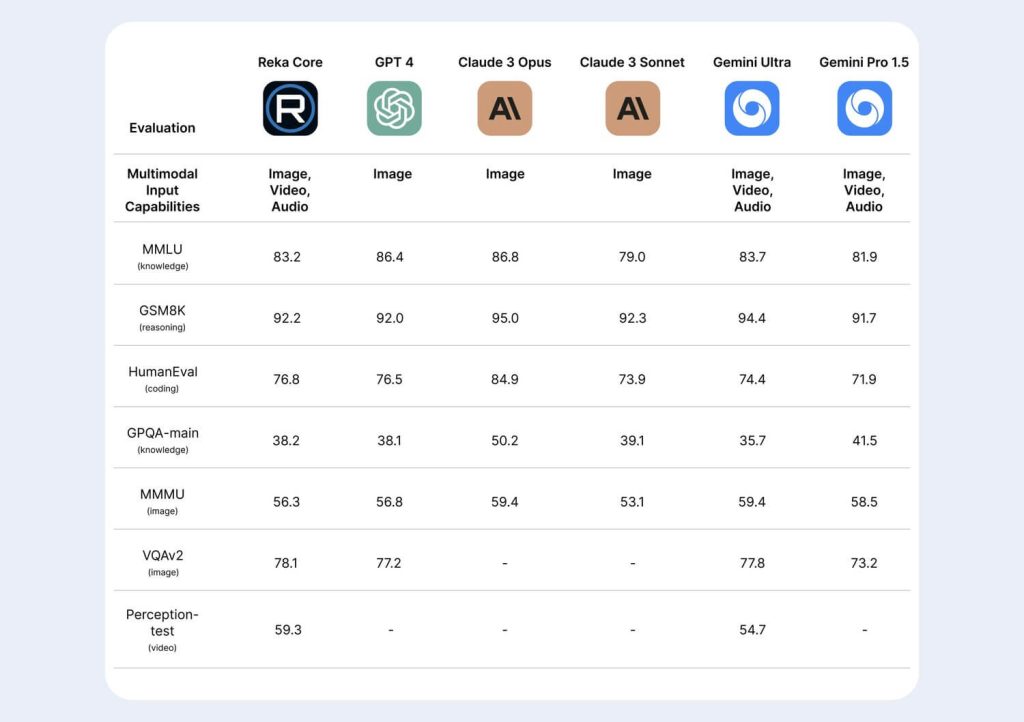
Core outperforms GPT4-V on picture question-answering benchmarks (e.g., MMMU, VQAv2). In contrast, Core is ranked as the second most popular model on multimodal chat, surpassing models like Claude 3 Opus.
In terms of text benchmarks, Core outperforms GPT4-0613 on human evaluation in addition to performing competitively against other frontier models on several well-known benchmarks (MMLU, GSM8K, etc.). Core does better than Gemini Ultra when it comes to answering video questions (Perception Test).
Here’s another benchmark called ELO that shows rankings on Human Evaluation for Multimodal. A higher ELO score represents better performance. You can see that Reka defeats Claude Opus and Gemini Pro 1.0, but it has still work left to do in catching up with GPT-4V.
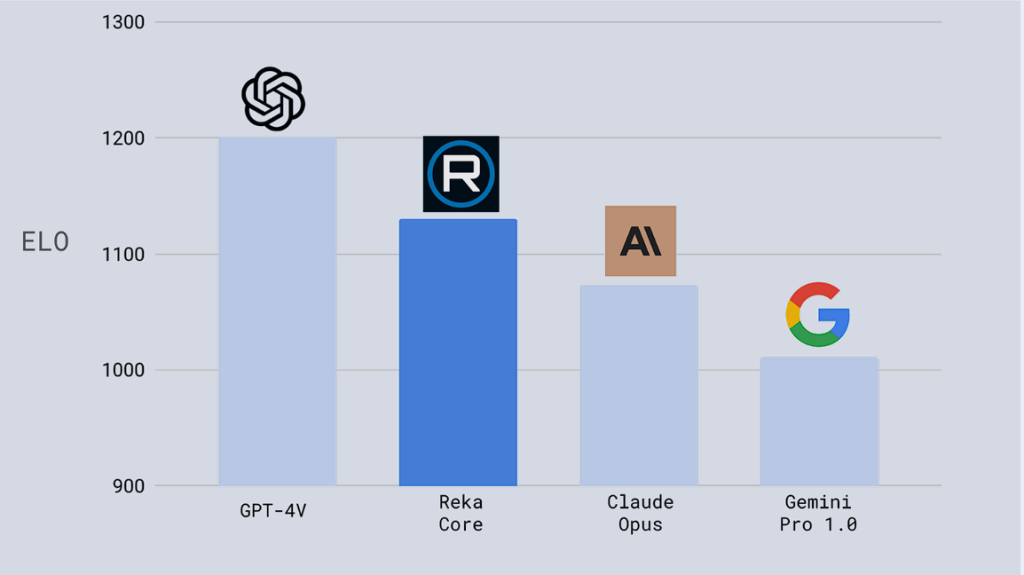
Overall, we get the idea that this is a highly powerful model based on its competitive benchmarks, and developers should integrate this AI model in their day-to-day Gen AI tasks such as Multimodal capabilities, coding-related tasks, reasoning tasks, and general knowledge questions.
Comprehending Reka Core’s Architecture
The overall architecture of Reka Core is a modular encoder-decoder architecture that accepts inputs in the forms of text, images, video, and audio. The model only allows text outputs at this time.
The core Transformer model makes use of SwiGLU, Grouped Query Attention, Rotary positional embeddings, and RMSNorm, and is built on the ‘Noam’ architecture.
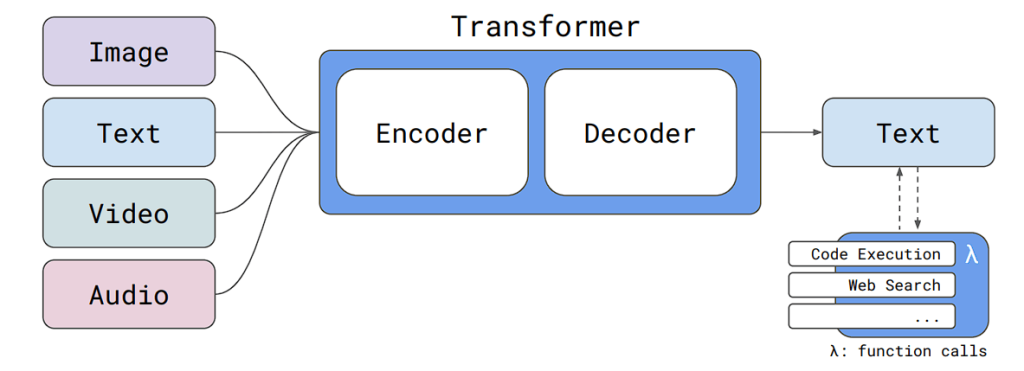
This architecture bears a resemblance to the PaLM architecture, excluding the parallel layers. A 100K sentence piece vocabulary based on tiktoken (e.g., GPT-4 tokenizer) is used by Reka Flash and Edge.
Sentinel tokens are added by Reka for particular use situations like tool use and masking spans. A multi-stage curriculum with varying mixture distributions, context lengths, and objectives is used in pretraining.
The Training Data
With a dataset knowledge cutoff of November 2023, Reka Core’s training data is a combination of proprietary/licensed and publicly available datasets. Text, photos, videos, and audio snippets make up the dataset that the model learned from.
The training datasets for Reka Flash and Reka Edge were roughly 5 trillion and 4.5 trillion thoroughly deduplicated and filtered language tokens, respectively.
30% of the pretraining data are STEM-related, and about 25% are code-related. A quarter or so of the data comes via web crawling. Reka’s data has a 10% mathematical component. It is important to note that Reka Core has not finished training and is still improving
Thirty-two different languages are tier-weighted (about based on frequency in the wild) and make up 15% of Reka Core’s expressly (and purposefully) multilingual pretraining data. In addition to these expressly up-weighted languages, Reka Core received training in all 110 languages found in the multilingual Wikipedia.
The multimodal training data consists of substantial sets of web pages, documents, videos, and photos. Quality, diversity, and scale are carefully optimized for the selected data mixture.

Reka Core’s Groundbreaking Features
Reka Core comes with several capabilities and features that users from the developer community can highly make use of. Let’s take a look at all of them:
- Multimodal (image and video) understanding: Reka Core is more than just a large-scale frontier language model. It is one of only two commercially available full multimodal solutions with a robust contextualized understanding of images, videos, and sounds.
- 128K context window: Reka Core is capable of ingesting and precisely and accurately recalling much more information. Reka’s baseline models have an 8K context length. Long context models namely Reka Flash and Reka Core have a 128K context window for retrieval and lengthy document tasks. Every model supports the context in which it is used by passing needle-in-the-haystack (passkey retrieval). These tests appear to support the extrapolation of their 128K context length to 256K context length, but not higher.
- Reasoning: Because of Core’s exceptional thinking skills in both English and maths, it can be used for complicated problems requiring in-depth analysis. Even though it has catching up to do with OpenAI in reasoning capabilities, it still is a key AI model in the generative AI market.
- Coding and agentic workflow: One of the best code generators is Core. When paired with other abilities, its coding skills can strengthen agentic workflows. So, developers go ahead and ask your DSA-related doubts in several programming languages and topics.
- Multilingual: 32 different language sets of text were used to pretrain Core. In addition to speaking various Asian and European languages fluently, it speaks English. We already mentioned before that it received training in 110 languages found in the multilingual Wikipedia.
Conclusion
Reka Core is the latest advancement in the field of Generative AI. Its highly competitive benchmarks place it on a level field compared to the top-notch AI companies in today’s world.




