



Google DeepMind Researchers successfully trained 20-inch tall humanoid robots to play 1v1 soccer matches using a deep reinforcement learning approach. With the help of this, the robots learned to run, kick, block, get up from falls, and score goals without the need for any manual programming.
Soccer players have to master a range of dynamic skills, from turning and kicking to chasing a ball. How could robots do the same? ⚽
— Google DeepMind (@GoogleDeepMind) April 11, 2024
We trained our AI agents to demonstrate a range of agile behaviors using reinforcement learning.
Here’s how. 🧵 https://t.co/RFBxLG6SMn pic.twitter.com/4B4S2YiVLh
Robots Soccer Training Approach
Researchers at Google DeepMind have designed a technique to train low-cost off-the-shelf bipedal robots to play multi-robot soccer well beyond the level of agility and fluency that is intuitively expected from this type of robot. They used a deep reinforcement learning-based (RL) approach and performed their tests on the widely available Robotis OP3 robots.
The researchers explained that generating robust motor skills in bipedal robots is a challenging task because of the inability of current control methods to generalize to specific tasks. The researchers utilized a deep RL technique to control the body of the Robotis OP3 robots thus allowing them to play one-on-one matches.
With the help of the training method, they aimed at making robots learn a wide variety of tasks such as walking, kicking, getting up from a fall, scoring goals, and defending. They divided the training pipeline into two stages:
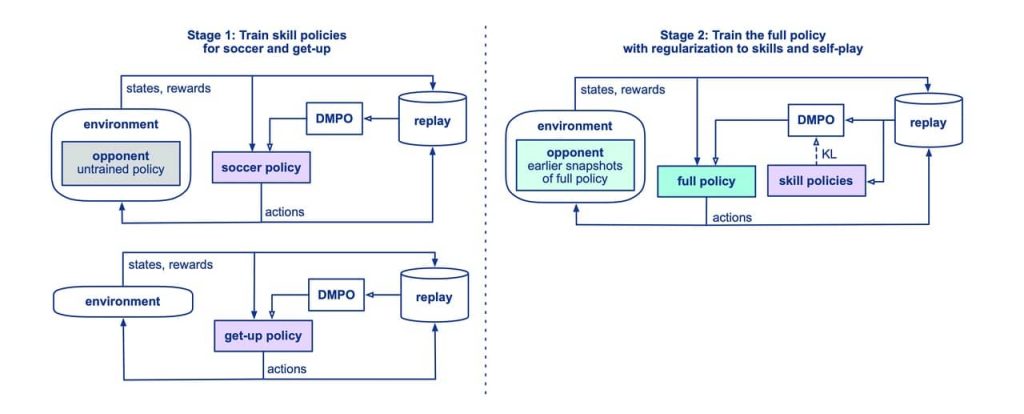
They first trained two separate skill policies: one for getting up from the ground and another for scoring a goal against an untrained opponent.
For the get-up skill, they used a sequence of target poses to bias the policy towards a stable and collision-free trajectory. For the soccer skill, the agent was trained to score as many goals as possible against an untrained opponent.
In the second stage, these skills were distilled into a single agent, which was then trained using self-play, where the opponent was drawn from a pool of partially trained copies of the agent itself.
During this stage, the agent played against increasingly stronger opponents, which were sampled from a pool of partially trained copies of the agent itself (self-play).
They used policy distillation to enable the agent to learn from the skill policies, regularizing the agent’s policy towards the relevant skill policy depending on the agent’s state.
This allowed the agent to integrate previously learned skills, refine them for the complete soccer task, and anticipate the opponent’s actions. They utilized various techniques such as shaping rewards, domain randomization, and random perturbations to enhance exploration and ensure safe transfer to real robots.
To improve the robustness of the policies and facilitate safe transfer to real robots, the researchers employed techniques such as domain randomization, perturbations during training, and shaping reward terms.
The robots were trained in a simulated environment using the MuJoCo physics engine and then the resulting policy was directly deployed on real Robotis OP3 miniature humanoid robots without any fine-tuning.
Here are The Results
The trained robots exhibited impressive performance in real-world tests. They outperformed specialized manually designed controllers in key behaviours such as walking (181% faster), turning (302% faster), getting up (63% less time), and kicking (34% faster with a run-up approach). T
The robots also demonstrated opponent awareness, adaptive footwork, and the ability to quickly recover from falls:
Our players were able to walk, turn, kick and stand up faster than manually programmed skills on this type of robot. 🔁
— Google DeepMind (@GoogleDeepMind) April 11, 2024
They could also combine movements to score goals, anticipate ball movements and block opponent shots – thereby developing a basic understanding of a 1v1 game. pic.twitter.com/1Bty4q9tDN
During 1v1 soccer matches, the robots showcased a variety of emergent behaviours, including agile movements, recovery from falls, object interaction, and strategic behaviours such as defending and protecting the ball with their bodies.
Remarkably, these robots exhibited higher speed compared to those controlled by traditional scripted methods, indicating the potential utility of this framework for orchestrating more intricate interactions among multiple robots.
They smoothly transitioned between different behaviours and adapted their tactics based on the game context. This approach enabled emergent behaviours to be discovered and optimized for specific contexts, allowing the agent to learn and adapt more effectively.
The results showed that pretraining separate soccer and get-up skills was crucial for success, as attempting to learn end-to-end without these separate skills led to suboptimal solutions. By using a minimal set of pre-trained skills, they simplified reward design, improved exploration, and avoided poor locomotion outcomes.
The ability of the robots to learn and adapt to various complicated situations, combine different skills, and make strategic decisions during soccer gameplay highlights the potential of deep reinforcement learning in the field of AI-based robotics.
Such an approach leads to advancements in the development of general robots, rather than training them for specific tasks.
Google Deepmind team is also working on the TacticAI System that provides experts with tactical insights mainly on corner kicks.
Conclusion
The success achieved by researchers at Google DeepMind marks a significant step forward in the creation of intelligent autonomous robots. The deep reinforcement learning approach to training, combined with techniques like domain randomization and self-play, can enable robots to learn complex tasks and adapt to dynamic environments.




