



Researchers at Meta AI recently released OpenEQA- the Open-Vocabulary Embodied Question Answering Benchmark.
It is a new open-source benchmark dataset that measures an AI agent’s understanding of physical environments by presenting it with questions such as “Did I close the fridge?”
Today we’re releasing OpenEQA — the Open-Vocabulary Embodied Question Answering Benchmark. It measures an AI agent’s understanding of physical environments by probing it with open vocabulary questions like “Where did I leave my badge?”
— AI at Meta (@AIatMeta) April 11, 2024
More details ➡️ https://t.co/vBFG7Z58kQ… pic.twitter.com/wsFPKue65q
OpenEQA aims to lead the integration of Embodied AI (EAI) agents into everyday devices like smartphones, smart glasses, and robots, catering to non-expert users. By harnessing foundation models trained on extensive datasets, OpenEQA seeks to improve these agents with human-like perception and understanding, essential for natural language interaction.
It introduces Embodied Question Answering (EQA) as a dual-purpose tool, both as a practical application and an evaluation metric for agent comprehension.
Through OpenEQA, Meta AI envisions empowering devices with episodic memory (EM-EQA) for platforms like smart glasses, enhancing user knowledge, and enabling active exploration (A-EQA) for mobile robots, facilitating autonomous information gathering and interaction.
What is EM-EQA?
In the EM-EQA task, agents utilize episodic memory to understand their environment and respond to queries. This scenario is especially pertinent for embodied AI agents integrated into devices like smart glasses, that lack autonomous exploration capabilities and depend on past observations to aid users.
For Example, ‘Q: Where did I leave my keys? A: On the kitchen island.’
What is A-EQA?
In the A-EQA scenario, agents address questions by actively exploring and gathering information. The OpenEQA benchmark focuses on queries necessitating navigation actions, but it can extend to mobile manipulators, enabling navigation and manipulation tasks, such as opening doors and cabinets.
For Example, ‘Q: Do we have canned tomatoes at home? A: Yes, I found canned tomatoes in the pantry.’
How was the OpenEQA dataset designed?
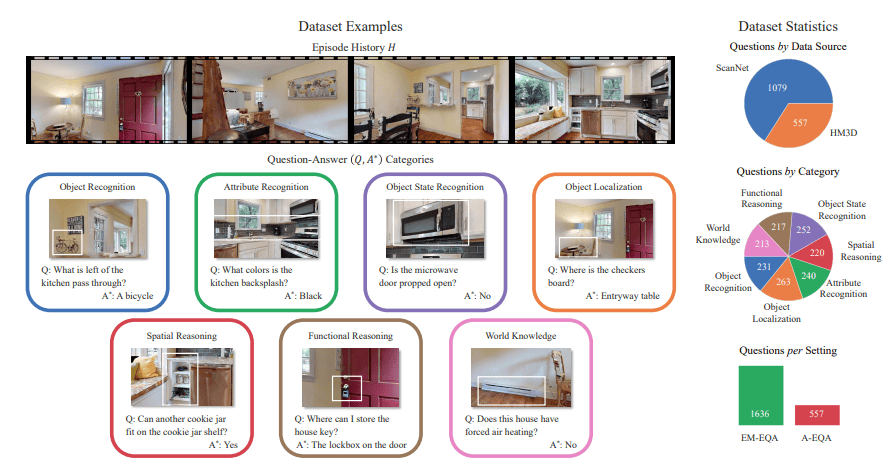
Data Collection: Episode histories were gathered from two primary sources: ScanNet and HM3D. For ScanNet, RGB-D data from human exploration in indoor settings were directly translated into episode histories, with 90 validation scenes and 10 test scenes selected.
For HM3D scans rendered through Habitat, a heuristic exploration policy mimics human behaviour, resulting in episode histories for 87 validation scenes.
Question Generation: Human annotators were shown episode histories and asked to generate question-answer pairs (Q, A*) as end users. Seven EQA question categories were identified, covering object recognition, attribute recognition, object state recognition, object localization, spatial reasoning, functional reasoning, and world knowledge.
The OpenEQA dataset focuses on these categories, with two questions and answers generated per category.
Dataset Validation: Two independent annotators examined each question to identify unanswerable, ambiguous, or incorrect questions. Any problematic pairs were discarded, resulting in a final dataset of 1636 validated questions.
Dataset Splits: Validated question-answer pairs were used for EM-EQA, with the same pairs reused for A-EQA, utilizing start states recorded in addition to episode histories.
Object localization: Object localization questions presented a unique challenge, with 4 additional correct answers collected from 2 additional annotators resulting in 5 answers per object localization to reflect natural distributions.
The image below shows the various examples and dataset-related statistics of OpenEQA:
Evaluation of correct answers using LLM-Match
While the open-vocabulary nature of EQA made it realistic, evaluating the correctness was challenging due to the possibility of multiple correct answers. To address this, they used a Large Language Model (LLM) for evaluating the answers generated by EQA agents.
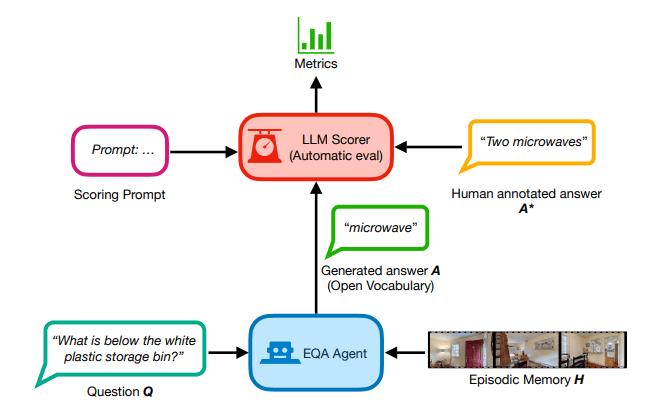
They adapted the evaluation protocol from MMBench, a collection of benchmarks for evaluation, to assign a score ranging from 1 to 5, where 1 indicates an incorrect response, 5 represents a correct response, and intermediate values reflect varying levels of similarity.
The aggregate correctness metric (LLM-Match) is calculated based on these scores to assess the overall performance of the EQA agents.
The prompt used for LLM-Match is as follows:

Evaluating the Efficiency of A-EQA
In A-EQA, agents were assessed based on two factors: (a) how accurate their answers were compared to human annotations, and (b) their efficiency, which considers how quickly they answered questions while favouring agents that explore efficiently.
Efficiency is calculated by considering the correctness score and the length of the agent’s path, relative to a ground truth path. This metric accounts for both accuracy and speed in navigation tasks.
The various EQA Agents used and evaluated were:
- Blind LLMs (LLaMA-2 and GPT-4): These agents provide answers solely based on the text of the question, without any visual context. They serve as a baseline for evaluating the performance of other agents, relying on prior knowledge or random guessing for responses.
- Socratic LLMs w/ Frame Captions (GPT-4 w/ LLaVA-1.5): These agents leverage captions generated from episodic memory frames and aim to provide more informed responses than blind LLMs. They incorporate textual descriptions of scenes to assist in answering questions.
- Socratic LLMs w/ Scene-Graph Captions (GPT-4 w/ ConceptGraph [CG] or Sparse Voxel Map [SVM]): These agents utilize object-centric scene-graph representations of episodic memory, allowing for a better understanding of objects. They construct textual scene graphs from which LLMs can reason over, potentially improving the response accuracy.
- Multi-Frame VLMs (GPT-4V): These agents directly process the entire episodic memory, including visual frames, to answer questions. They offer a comprehensive approach to EQA as they are capable of handling multiple frames.
- Human-Agent: Human participants provide answers to questions based on the episode history, establishing a benchmark for human-level performance in EQA.
- Agents for A-EQA: These agents must generate their observations through exploration, as no explicit episode history is provided. Frontier exploration is used as a baseline approach, with agents generating their episodic memory for answering the questions.
To combat overly conservative behaviour where agents refrain from answering, the Force-A-Guess approach forces agents to make an informed random guess rather than immediately counting abstaining as a failure.
Results Explained
The image shows a detailed breakdown of EM-EQA performance across the seven question categories. EQA agents demonstrate particular strength in functional reasoning and object state recognition, achieving LLM-Match scores averaging around 50%.
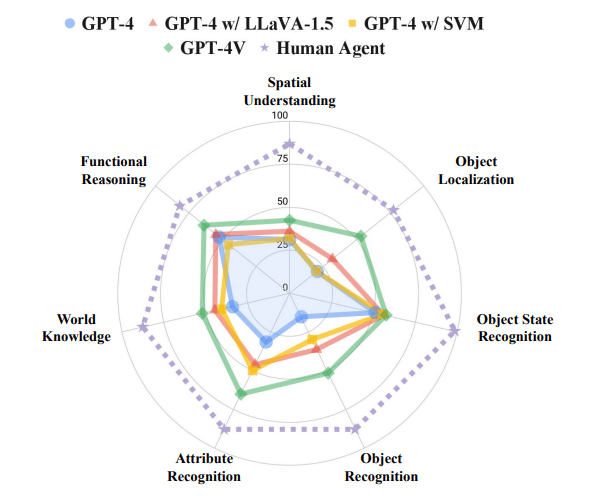
Moreover, they perform well in world knowledge questions, showcasing the potential for large language models to contribute significantly.
However, EQA agents struggle notably with spatial reasoning questions. Surprisingly, agents utilizing scene-graph representations show no significant improvement over those using frame-captioning methods, indicating the necessity for further development in understanding spatial concepts and geometry within large models.
Despite these achievements, there remains a considerable performance gap between the best-performing methods and human-level performance.
Meta is coming with many new announcements, whether it’s Llama 3 coming soon, or their AI chatbot coming to WhatsApp.
Conclusion
OpenEQA represents a significant step forward in evaluating an AI agent’s comprehension of physical environments through Embodied Question Answering (EQA).




