



Just like humans, now AI can be trained to predict what will happen! At least, that’s what this new system can do.
Highlights:
- Researchers at the University of Berkeley developed an AI forecasting system that might equal human-level wisdom.
- They built a retrieval-augmented LM system using GPT-4 to generate forecasts and predict future events.
- The results show that the predictions might surpass human scores across diverse aspects.
AI Forecasting System built with GPT-4
The world of generative AI keeps on evolving as Language Models keep coming up with new capabilities daily. This new study shows us another aspect of LMs as they can be useful for building AI forecasting systems.
A group of researchers from the University of Berkeley, California, made an AI forecasting system that can compete with human-level forecasting capabilities, without the shortcomings such as expenses, time delays, and application-specific domain problems.
Since LLMs aren’t designed with event forecasting in mind, the scientists used retrieval-augmented reasoning to build a forecasting system on top of GPT-4. Through a series of steps, GPT-4 was trained to find relevant information, evaluate its applicability, and incorporate it into its reasoning process before generating a forecast.
“Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions.”
Recently, a similar significant research shows that AI models can communicate with each other, so, a lot is happening in these times.
How is AI Forecasting an Improvement?
Till now whenever humans have performed forecasting, they have done it in two methods, namely statistical and judgmental.
Time-series modelling techniques are the main tools used in statistical forecasting. This methodology works best when there is a large amount of data with little distributional movement.
In contrast, human forecasters use historical data, subject expertise, Fermi estimates, and intuition to assign probabilities to future events based on their judgments. They gather data from various sources and make decisions depending on the specific work situations.
This makes it possible to make reliable projections even in the case of few historical observations or large distributional shifts.
However, Forecasting can be costly, slow, or only useful in certain fields since it depends on human labour and experience. Furthermore, the majority of human projections have little to no explanatory content. This is where the need for language models in AI forecasting systems comes in.
LMs can quickly and affordably make forecasts due to their rapid text parsing and production capabilities. They have extensive, cross-domain knowledge since they have been pre-trained on web-scale data.
Additionally, we can study them to partially comprehend the final forecast because we can elicit their reasonings through prompts.
Looking Into the Forecasting Model
The scientists focused on anticipating binary outcomes when they constructed an LM pipeline for automated forecasting.
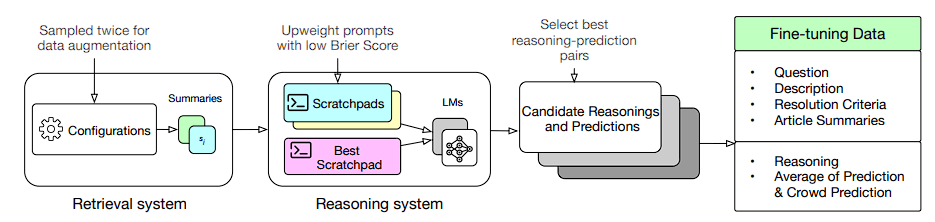
Three essential elements of the conventional forecasting method are implemented and automated by their system.
The three steps are as follows: retrieval, which compiles pertinent information from news sources; reasoning, which assesses the facts at hand and creates a forecast; and aggregation, which combines several predictions into a single prediction.
Every stage utilizes a set of prompted or fine-tuned learning modules (LMs). Let’s look into each step, in detail:
1) Retrieval
Four phases make up the retrieval system: creating search queries, retrieving news, reranking and filtering content based on relevancy, and summarising material. To access historical articles, the news APIs are first called upon by the system’s generated search queries.
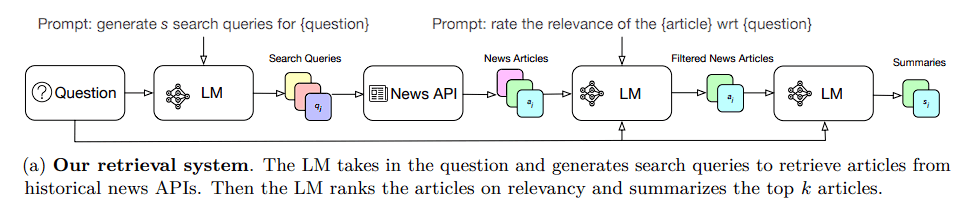
Using a simple query expansion prompt at first, the researchers told the model to generate questions depending on the question and its context. The researchers instructed the model to break down the forecasting question into smaller queries and use each to create a search query to obtain wider coverage.
Next, using the search queries provided by LM, the system pulls articles from news APIs. The researchers chose NewsCatcher and Google News after evaluating five APIs for the relevancy of the articles they retrieved.
At the expense of getting certain irrelevant articles, the initial retrieval offers extensive coverage. They instructed GPT-3.5-Turbo to rate the relevancy of every article and eliminate those with poor scores to make sure they do not deceive the model during the reasoning step.
The researchers summed up the papers since LMs are constrained by their context window. They instructed GT-3.5-Turbo to extract the most pertinent information on the forecasting topic from every article. In the end, they ranked the top k article summaries according to relevance and gave them to the LM.
2) Reasoning
The reasoning paths of the model were organized by the researchers using an open-ended scratchpad. Their prompt starts with asking about the issue, giving an explanation, outlining the resolution requirements and important deadlines, and then listing the top k pertinent summaries.
Four more components were added to the ideal scratchpad prompt to help the model reason about the forecasting question.
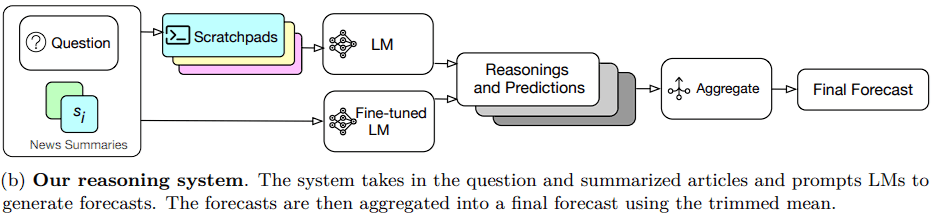
To be sure the model understood the question, the researchers first had it restate the inquiry. To provide more details, it is also told to broaden the inquiry using what it knows. It makes sense that a question with more specific and elaborate wording would elicit better answers.
They then instructed the model to use the data it had recovered and its prior training to generate justifications for why the desired result may or might not come to pass. To mitigate the risk of bias and miscalibration, the model was instructed to assess its level of confidence and take past base rates into account. If necessary, this allowed the model to calibrate and modify the prediction.
GPT-4 evaluates the condensed articles and generates a comprehensive forecast with a justification by using “scratchpad prompts.” These questions direct the model’s reasoning and promote a methodical approach to reasoning.
3) Aggregation
After fine-tuning GPT-4, the researchers trained it to produce reasonings with precise predictions. They gave it just the essential details of the inquiry as prompts, excluding any scratchpad instructions, because their refined model was designed to reason without explicit guidance.
With the addition of self-supervised fine-tuning, the Berkeley team advanced the system even further. The “wisdom of the crowd,” which is defined as the collective forecasts of human forecasters, was exceeded by the AI in many of the cases where they created a significant number of projections on historical queries with known answers.
They elicited multiple predictions from both the base and the fine-tuned models. Due to its superior performance on the validation set when compared to the other ensemble methods that the researchers tried, the system combined these forecasts into a final prediction by taking their trimmed mean.
Overall, the researchers trained GPT-4 to imitate the reasoning patterns that produced the most accurate projections by fine-tuning them using these instances.
What did the Results show?
The forecasting model showed excellent results in proving to be a worthy human wisdom-level AI forecasting system. When the AI had access to enough pertinent publications on a given topic and was asked questions with high human uncertainty early in the forecasting process, it did especially well.
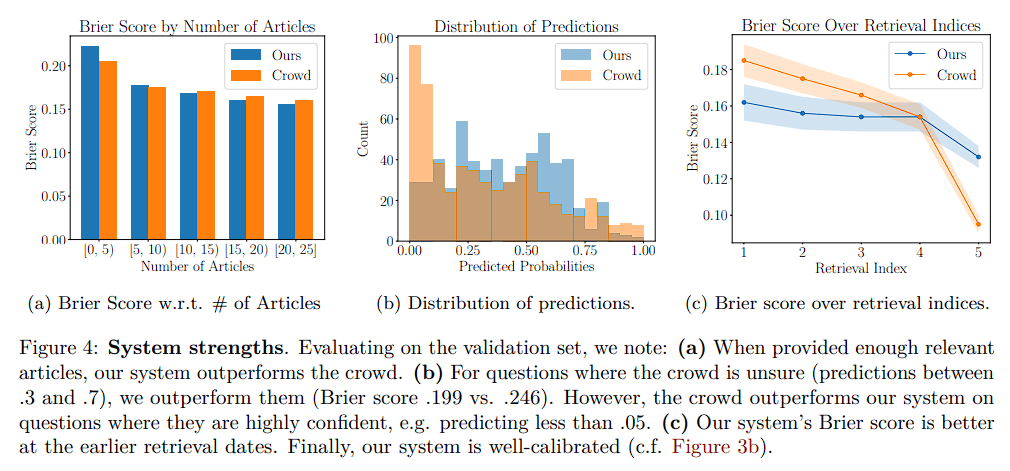
The AI received a Brier score of 0.179 when evaluated on forecasting questions starting in June 2023, whereas the human forecaster had a score of 0.149.
When the system had between 0 and 10 relevant articles, it outperformed a group of people. The algorithm performed better when users had uncertain predictions with confidence levels between 0.3 and 0.7. The model’s Brier score was 0.199, whereas users’ scores were 0.246.
However, individuals outperformed the model when they were quite certain with predictions under 0.05.
When data was first being gathered, the accuracy of the system was higher.
Conclusion
Although using AI to forecast significant societal and personal events is still a complex idea to tackle with, this is a major advancement in the world of generative AI, and we can’t help but appreciate the progress!




