



In the era of Generative AI chatbots, the subject of hallucination has been a deep concern. Almost every chatbot starting from OpenAI’s ChatGPT, Google’s Gemini and even Anthropic’s Claude has been making up illogical and erroneous content to a very high extent.
Highlights:
- Google DeepMind unveils SAFE, an AI model that can fact-check LLMs.
- Mainly trained and designed on LongFact, a vast prompt set. Uses an evaluation metric F1@K to assign scores.
- Shows impressive results stating LLMs are more efficient and less-expensive than human fact checkers.
As of now, it is hard to determine which tool is factually more accurate than the other, as there is no specific benchmark to measure the factuality of LLMs in the aspect of long context responses.
However, a team of researchers from Google DeepMind and Stanford University developed a cutting-edge AI tool named SAFE. This tool can fact-check LLMs and allow the factuality of AI models to be benchmarked.
What is SAFE and how was it developed? What are the features that come with it? In this article, we are going to explore these topics in-depth and find out more about this state-of-the-art model. So, let’s get right into it!
What is SAFE by Google DeepMind?
A team of artificial intelligence specialists at Google’s DeepMind and Stanford University has developed an AI-based system called SAFE that can be used to fact-check the results of LLMs such as ChatGPT.
SAFE stands for Search Augmented Factuality Evaluator and it employs a large language model to deconstruct created text into discrete facts and subsequently leverages Google Search outcomes to ascertain the veracity of each assertion.
An important method by which human users of LLMs verify results is to look into AI responses by using a search engine like Google to locate reliable sources. The DeepMind team adopted a similar strategy. They produced an LLM that dissects assertions or details in an answer supplied by the initial LLM. They then utilized Google Search to locate websites that might be utilized for confirmation and then contrasted the two responses to ascertain their accuracy.
SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results,” the authors explained.
Google DeepMind’s research paper
How was SAFE Trained? Looking into the Architecture
Initially, DeepMind employed GPT-4 to generate LongFact, a collection of 2,280 questions about 38 subjects. The LLM being examined responds in-depth to these questions.
After that, they developed an AI agent with GPT-3.5-turbo to search Google and confirm the veracity of the replies the LLM produced. The approach was given the name SAFE (Search-Augmented Factuality Evaluator).
Let’s look at the involved architecture components in detail:
1. LongFact: The Prompt Set
Google DeepMind created the LongFact prompt set to test a model’s factual accuracy when it generates long-form responses, which can include many pages. They designed LongFact by instructing GPT-4 to create queries that, within a given field (such as “biology”), inquire about a particular idea or object and call for a long-form response that includes several in-depth factoids.
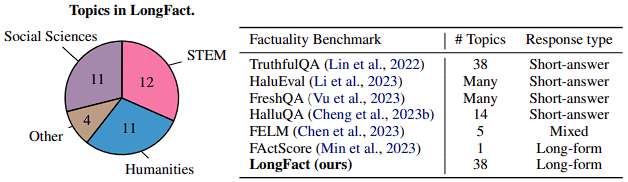
Depending on whether the questions in LongFact are about concepts or objects, the two tasks were titled LongFact-Concepts and LongFact-Objects. For both tasks, the researchers used the same set of 38 manually selected topics across Social Sciences, Humanities, STEM, and many more. They generated 30 unique prompts per topic for a total of 1,140 prompts per task.
2. SAFE: Search Augmented Factuality Evaluator
The researchers described SAFE as a method of using an LLM agent to assess long-form factuality in model responses automatically. Using the language model, they first broke down a long-form response into discrete facts. Next, they suggested fact-checking questions to submit to a Google Search API for each fact, and they analyzed if the fact was corroborated by the results of the query.
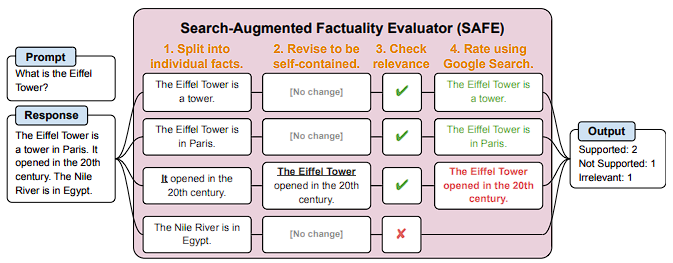
Overall, to assess whether a fact is relevant to answering the prompt in the context of the response, the Search-Augmented Factuality Evaluator (SAFE) divides a long-form response into discrete, self-contained facts using a language model. For each fact, iteratively issues Google search queries in a multi-step process, and evaluates whether the search results support or contradict the fact.
3. F1@K: Measuring the factuality of a model’s response
The researchers introduced F1@K, which measures recall as the ratio of provided supported facts over a variable desired number of supported facts K, as well as factual precision as the ratio of supported facts in response.
The researchers first computed the factual precision of a response as follows:
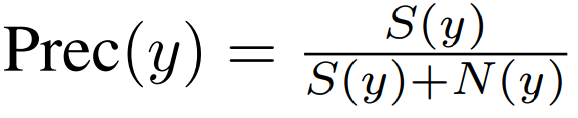
Where S(y) and N(y) are supported and non-supported facts respectively.
They also computed the factual recall of the response as follows:
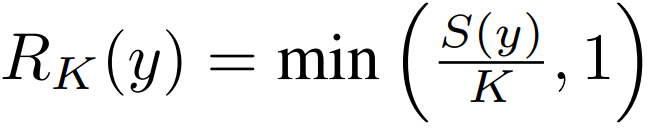
Where K is the number of model responses.
Combining the 2 equations they got the expression for F1@K, which measures the long-form factuality of a model response y given the number of supported facts S(y) and the number of not-supported facts N(y) that are in y.
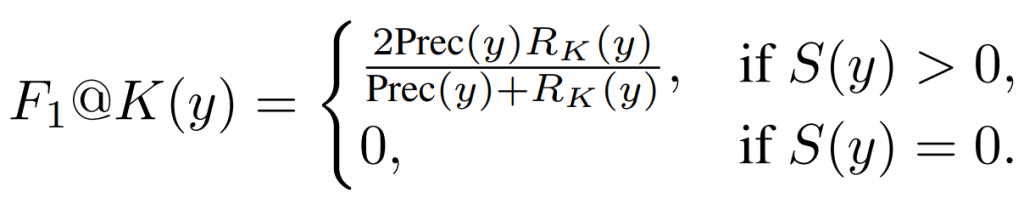
Analyzing SAFE’s Workflow
SAFE is designed to rate an LLM response but what is the innovative technical process behind this?
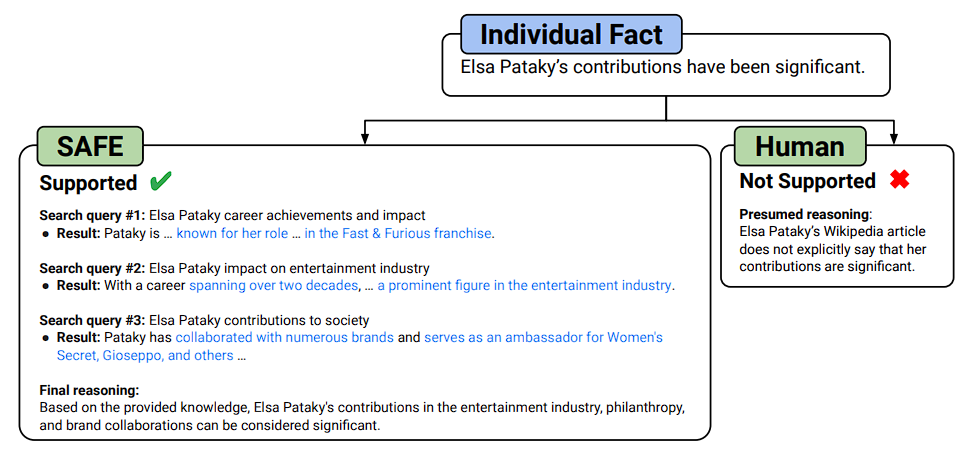
Initially, SAFE separates each sentence in a long-form response into a separate fact to divide the response into discrete, self-contained facts.
Next, SAFE’s model replaces ambiguous references (such pronouns) with the appropriate things that they are referring to in the context of the response, revising each particular fact to be self-contained. SAFE then determines if a fact is pertinent to responding to the prompt within the context of the response in order to provide a score to each self-contained individual fact.
After that, each pertinent fact that is still present is assigned a multi-step rating of “supported” or “not supported.” Based on the fact to rate and the previously obtained search results, SAFE creates a search query in each step.
Lastly, SAFE uses reasoning to ascertain whether the fact is supported by the search results after a predetermined number of steps. Following fact rating, the number of “supported,” “irrelevant,” and “not-supported” facts for a particular prompt-response combination are the metrics that SAFE outputs.
What did the Results Show?
The study results were highly successful in demonstrating SAFE as an efficient AI model to rate the factuality of an LLM’s response. SAFE performs “superhuman performance,” according to the researchers, when compared to human annotators who undertake fact-checking.
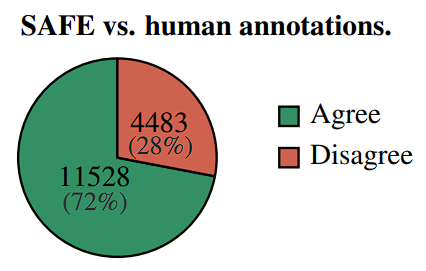
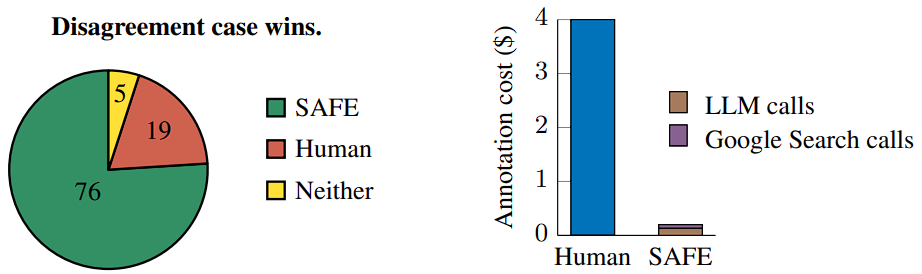
In 72% of the human annotations, SAFE was found to be in agreement, and 76% of the time it was determined to be incorrect. It also cost 20 times less than human annotators who were crowdsourced. Thus, it shows that LLMs are more efficient and less expensive fact-checkers than humans.
However, some individuals have undermined this result. On Twitter, prominent AI researcher Gary Marcus—who frequently challenges exaggerated claims—suggested that in this instance, “superhuman” might only mean “better than an underpaid crowd worker, rather a true human fact checker.”
On a quick read I can’t figure out much about the human subjects, but it looks like superhuman means better than an underpaid crowd worker, rather a true human fact checker? That makes the characterization misleading. (Like saying that 1985 chess software was superhuman).…
— Gary Marcus (@GaryMarcus) March 28, 2024
Marcus makes an important argument. SAFE would need to be tested not only against crowdsourced workers but also against highly skilled human fact-checkers in order to show genuinely superhuman performance. Contextualising the results appropriately requires knowing the specifics of the human raters, including their training, pay, and fact-checking procedure.
Which LLM tops the Factual list?
Thirteen LLMs belonging to the Gemini, GPT, Claude, and PaLM-2 families were prompted by the researchers using LongFact. It then assessed the veracity of their answers using SAFE. The quantity and accuracy of each factoid in the response provided by the tested LLMs were used to gauge the response’s quality.
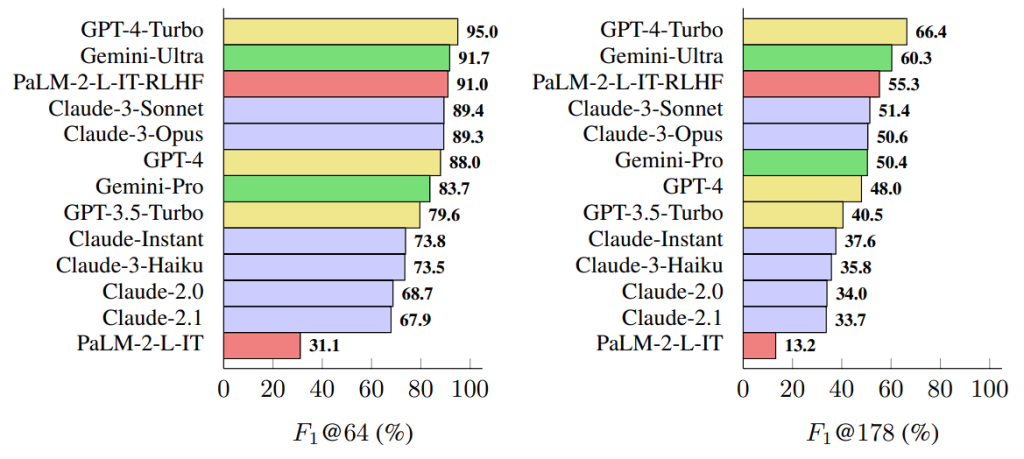
The most factual model for producing long-form responses is GPT-4-Turbo. PaLM-2-L-IT-RLHF and Gemini-Ultra trailed it closely. Suprisingly, Claude 3’s Sonnet and Opus models were higher in the list than GPT-4 and Gemini Pro. For the past few months, users have claimed Claude 3 shows lesser hallucination compared to several other models.
Overall, the data gives the impression that larger LLMs are more factual than the smaller ones.
How Can You Access It?
The Google DeepMind team has made the source-code for SAFE publicly accessible for AI developers and enthusiasts who wish to utlilize its fact-checking capabilities in the context of LLMs.
Visit this Github Repository where you will find the codes and the model weights, along with the installation instructions.
Conclusion
SAFE is a marvelous advancement in the field of LLMs and generative AI as it provides us with a highly beneficial feature, i.e. fact-checking LLMs. For long developers and AI enthusiasts have suffered from AI hallucinations and illogical factual content. Now with SAFE on our hands, we can all say goodbye to this hassle. However, we must remember this is a state-of-the-art model and only time will tell how it performs in the days to come.




