



The company behind DBRX said that it is the world’s most powerful open-source AI mode. Let’s look at how it was built.
Highlights:
- Databricks recently introduced DBRX, an open general-purpose LLM claimed to be the world’s most powerful open-source AI model.
- It outperforms OpenAI’s GPT-3.5 as well as existing open-source LLMs like Llama 2 70B and Mixtral-8x7B on standard industry benchmarks.
- It is freely available for research and commercial use through GitHub and HuggingFace.
Meet DBRX, The New LLM in Market
DBRX is an open and general-purpose LLM built by Databricks to encourage customers to migrate away from commercial alternatives.
The team at Databricks spent roughly $10 million and two months training the new AI model.
DBRX is a transformer-based decoder-only LLM that is trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input. It has been pre-trained on 12T tokens of text and code data.
Ali Ghodsi, co-founder and CEO of Databricks, spoke about how their vision translated into DBRX:
“At Databricks, our vision has always been to democratize data and AI. We’re doing that by delivering data intelligence to every enterprise — helping them understand and use their private data to build their own AI systems. DBRX is the result of that aim.”
Ali Ghodsi
DBRX uses the MoE architecture, a type of neural network that divides the learning process among multiple specialized subnetworks known as “experts.” Each expert is proficient in a specific aspect of the designated task. A “gating network” decides how to allocate the input data among the experts optimally.
Compared to other similar open MoE models like Mixtral and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. It has 16 experts and chooses 4, while Mixtral and Grok-1 have 8 experts and choose 2. This provides 65x more possible combinations of experts and this helps improve model quality.
It was trained on a network of 3072 NVIDIA H100s interconnected via 3.2Tbps Infiniband. The development of DBRX, spanning pre-training, post-training, evaluation, red-teaming, and refinement, occurred over three months.
Why is DBRX open-source?
Recently, Grok by xAI is also made open-source. By open-sourcing DBRX, Databricks is contributing to a growing movement that challenges the secretive approach of major companies in the current generative AI boom.
While OpenAI and Google keep the code for their GPT-4 and Gemini large language models closely guarded, rivals like Meta have released their models to foster innovation among researchers, entrepreneurs, startups, and established businesses.
Databricks aims to be transparent about the creation process of its open-source model, a contrast to Meta’s approach with its Llama 2 model. With open-source models like this becoming available, the pace of AI development is expected to remain brisk.
Databricks has a particular motivation for its openness. While tech giants like Google have swiftly implemented new AI solutions in the past year, Ghodsi notes that many large companies in various sectors have yet to adopt the technology widely for their data.
The aim is to assist companies in finance, healthcare, and other fields, that desire ChatGPT-like tools but are hesitant to entrust sensitive data to the cloud.
“We call it data intelligence—the intelligence to understand your own data,” Ghodsi explains. Databricks will either tailor DBRX for a client or develop a customized model from scratch to suit their business needs. For major corporations, the investment in creating a platform like DBRX is justified, he asserts. “That’s the big business opportunity for us.”
Comparing DBRX to other models
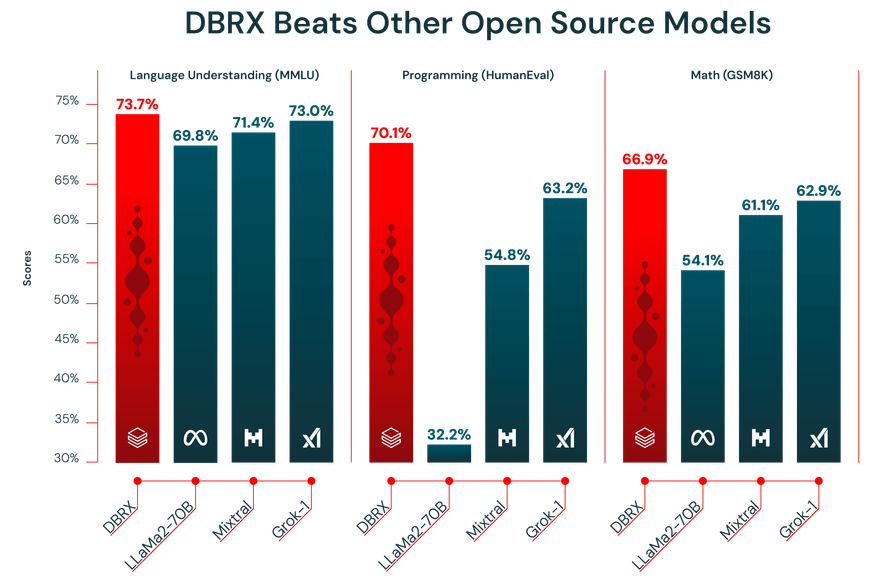
DBRX outperforms existing open-source LLMs like Llama 2 70B and Mixtral-8x7B on standard industry benchmarks, such as language understanding (MMLU), programming (HumanEval), and math (GSM8K). The figure below shows a comparison between Databricks’ LLM and other open-source LLMs.
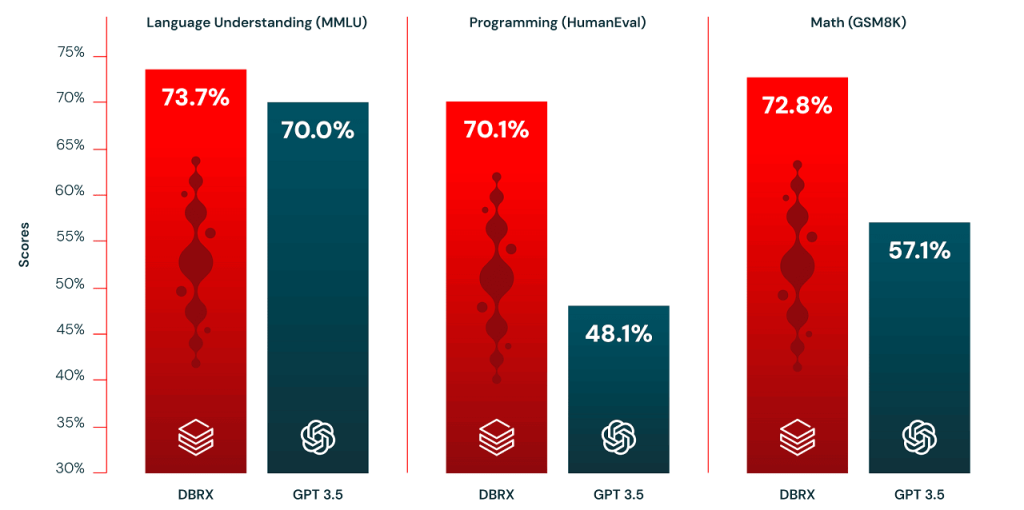
It also outperforms GPT-3.5 on the same benchmarks as seen in the figure below:
It outperforms its rivals on several key benchmarks:
- Language Understanding: DBRX achieves a score of 73.7%, surpassing GPT-3.5 (70.0%), Llama 2-70B (69.8%), Mixtral (71.4%), and Grok-1 (73.0%).
- Programming: It demonstrates a significant lead with a score of 70.1%, compared to GPT-3.5’s 48.1%, Llama 2-70B’s 32.3%, Mixtral’s 54.8%, and Grok-1’s 63.2%.
- Math: It achieves a score of 66.9%, edging out GPT-3.5 (57.1%), Llama 2-70B (54.1%), Mixtral (61.1%), and Grok-1 (62.9%).
DBRX also claims that for SQL-related tasks, it has surpassed GPT-3.5 Turbo and is challenging GPT-4 Turbo. It is also a leading model among open models and GPT-3.5 Turbo on Retrieval Augmented Generation (RAG) tasks.
Availability of DBRX
DBRX is freely accessible for both research and commercial purposes on open-source collaboration platforms like GitHub and HuggingFace.
It can be accessed through GitHub. It can also be accessed through HuggingFace. Users can access and interact with DBRX hosted on HuggingFace for free.
Developers can use this new openly available model released under an open license to build on top of the work done by Databricks. Developers can use its long context abilities in RAG systems and build custom DBRX models on their data today on the Databricks platform.
The open-source LLM can be accessed on AWS and Google Cloud, as well as directly on Microsoft Azure through Azure Databricks. Additionally, it is expected to be available through the NVIDIA API Catalog and supported on the NVIDIA NIM inference microservice.
Conclusion
Databricks’ introduction of DBRX marks a significant milestone in the world of open-source LLM models, showcasing superior performance across various benchmarks. By making it open-source, Databricks is contributing to a growing movement that challenges the secretive approach of major companies in the current generative AI boom.




