



In the competitive world of AI, Apple is now in the race! They quietly announced MM1- a series of multimodal AI models, competitive with Gemini 1. Let’s see how different or better it is!
Highlights:
- Apple announced MM1- its series of multimodal AI models.
- Supports up to 30 billion parameters, which combines vision with language understanding.
- MM1 performs in-context predictions because of its large-scale multimodal pre-training.
Apple’s MM1 AI Models Explained
Apple published its research paper on MM1 that introduces this family of models and provides significant insights into building competent systems.
Brandon Mckinzine, who is constructing Multimodal LLMs at Apple, put out this tweet on X announcing MM1:
Thrilled to share MM1!. The MM1 series of models are competitive with Gemini 1 at each of their respective model sizes. Beyond just announcing a new series of models, we also share the ablation results that guided our research process (🧵). pic.twitter.com/sYeJRDCbcP
— Brandon McKinzie (@mckbrando) March 15, 2024
After conducting thorough ablation studies and systematic experiments, the team has gained valuable insights into constructing effective multimodal models. Ablation is the removal of a component of an AI system to understand the contribution of the component to that respective system.
Their discoveries provide valuable information on the varying significance of architectural decisions, data integration methods, and scaling techniques.
What is Multimodal Learning?
Multimodal learning is a subdomain of AI focused on efficiently handling and interpreting data from various modalities simultaneously. This means combining information from various sources such as text, image, audio, and video to build a more complete and accurate understanding of the underlying data.
This concept has found applications in a wide range of subjects such as speech recognition, and emotion recognition. Multimodal learning techniques enable models to adeptly process and analyze data from diverse modalities, facilitating a comprehensive and precise comprehension of the underlying information.
In recent years, researchers have achieved impressive progress in language modelling and image understanding.
Due to the abundance of large-scale image-text datasets, we have witnessed the rise of highly effective Large Language Models (LLMs) and Vision Foundation Models. These models have now become the standard for addressing a wide range of language and image comprehension tasks.
Given the above developments, an area of multimodal foundation models has emerged that merges the above advances into a single model that will be superior compared to any separate model.
In particular, MLLMs are large-scale foundation models that consume image and text data and produce output text. MLLMs are succeeding LLMs as the next frontier in foundation models emerging as the next frontier in foundation models.
What We Found About Apple’s MM1?
Apple conducted small-scale experiments to analyze the impact of different factors on model performance. They found that when it comes to model architecture, factors like image resolution and the capacity of the visual encoder are crucial, while the method of feeding visual data into the model has less influence.
They also tested three types of pre-trained data: Image-captioned, Interleaved image-text, and Text-only.
They discovered that for tasks requiring limited training data, interleaved and text-only data are most important, whereas caption data is crucial for tasks requiring no prior training.
These findings were consistent even after fine-tuning the model, demonstrating that insights gained during pre-training remain valuable even in subsequent phases.
They scaled up their model MM1 using larger LLMs and explored a mixture of expert models, resulting in top-performing models across various tasks.
MM1 outperforms previous top AI models on captioning and visual question-answering tasks in few-shot settings. It exhibits desirable properties such as in-context predictions, multi-image reasoning, and strong few-shot learning capability.
These insights are expected to remain relevant as modelling techniques and data sources evolve.
Recipe for building MM1
Creating high-performing MLLMs involves a significant amount of experimentation. While the overall architecture and training approach are well-defined, the specific implementation details require careful consideration. Their work delved into three key aspects of design decisions:
- Architecture
- Data Selection
- Training Procedures
They investigated different pre-trained image encoders and methods of integrating them with LLMs, explored different types of data and their respective weights in the model’s mixture, and analyzed the training process, including hyperparameters and the timing of training different model components.
Setup for Ablations
To assess model performance efficiently, Apple utilized a simplified setup for ablations due to the vast resources required for training MLLMs.
They started with a smaller base configuration of the model and modified one component at a time, such as an architectural module or a data-related source. This enabled them to evaluate the impact of each design choice systematically.
The base configuration includes a ViT-L/14 image encoder trained with a CLIP loss on DFN-5B and VeCap-300M datasets, a C-Abstractor vision-language connector, and a mix of captioned images, interleaved image-text documents, and text-only data for pre-training.
Pre-training ablations: choice of image encoder, impact of image resolution, choice of vision-language bridge, impact of number of tokens per image, and impact of various pre-training data sources and their relative mixture weights. pic.twitter.com/BORby4oTg6
— Brandon McKinzie (@mckbrando) March 15, 2024
Additionally, a 1.2 billion transformer decoder-only language model is used. They evaluate the different design decisions based on zero-shot and few-shot performance across various Visual Question Answering (VQA) and captioning tasks.
Architecture
For architecture, they tested different pre-trained image encoders (varying objective, data, and resolution) and vision-language connectors.
For the vision-language connector (VLC), they tested different pooling techniques like average pooling, attention pooling, and a convolutional ResNet block called C-Abstractor. Surprisingly, the specific connector architecture had little effect on performance.
The inferences they made were as follows:
- The choice of the pre-trained image encoder significantly influenced downstream results, impacting both multimodal pre-training and instruction tuning outcomes. Image encoder size and pre-training data also matter, with a modest <1% lift going from ViT-L to ViT-H
- For the encoder, image resolution had the highest impact, followed by model size and training data composition. Image resolution gave a ~3% boost going from 224px to 336px.
- For the VL Connector, the number of visual tokens and image resolution mattered most, while the type of VL connector had little effect.
For pre-training data, they use mixes of captioned images, synthetic captioned images, interleaved image-text documents, and text-only data:
- Interleaved data is instrumental for few-shot and text-only performance. It gives a 10%+ lift
- captioning data lifts zero-shot performance the most
- text-only data helps with few-shot and text-only performance.
- A careful mixture of image and text data can yield optimal multimodal performance and retain strong text performance. Careful mixing of modalities (5:5:1 ratio of captions, interleaved, text) works best
- Synthetic data helps with few-shot learning (+2-4%)
Final Model
They collected the results from the previous ablations to determine the final recipe for MM1 multimodal pre-training:
- Image Encoder: Motivated by the importance of image resolution in pre-training, they use a ViT-H [27] model with 378x378px resolution.
- Vision-Language Connector: As the number of visual tokens is of the highest importance, they use a VL connector with 144 tokens.
- Data: To maintain both zero- and few-shot performance, they used the following careful mix of 45% interleaved image-text documents, 45% image-text pair documents, and 10% text-only documents.
The final MM1 family, scaled up to 30B parameters with both dense and mixture-of-experts (MoE) variants, achieved State-of-the-art (SOTA) few-shot results on key benchmarks versus models Flamingo, IDEFICS, and EMu2.
The authors demonstrated that their pre-training insights remained effective even after supervised fine-tuning (SFT). MM1 showcases compelling features such as multi-image reasoning, OCR capability, and object counting.
The intentional architecture and data choices in the MM1 recipe result in high performance when scaled up. The authors anticipate that these insights will have broader applicability beyond their specific implementation.
MM1 performs in-context predictions because of its large-scale multimodal pre-training. This helps MM1 to:
- Count objects and follow specified formatting
- Refer to parts of an input image and perform Optical Character Recognition (OCR)
- Show common sense
- Know everyday objects
- Perform basic mathematical operations
- Follow instructions and reason across images
Sources/References
The results shown in the research paper are as follows:
All the images are from the paper and the prompts and input images fed to MM1 are from the COCO 2014 Validation Dataset


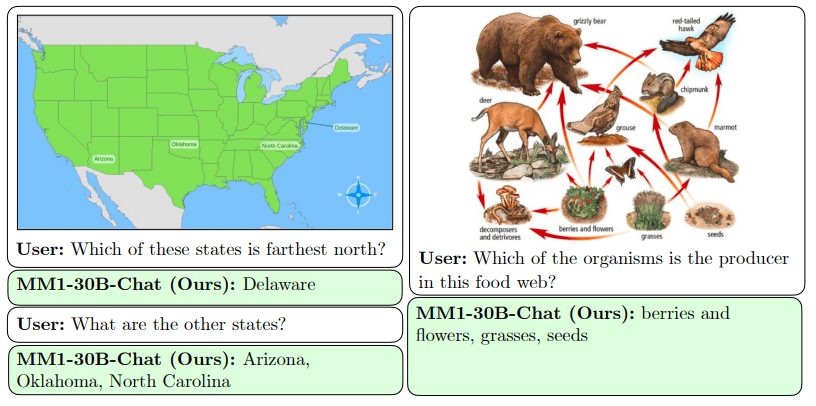
Examples of testing MM1 counting, OCR and scientific knowledge capabilities:


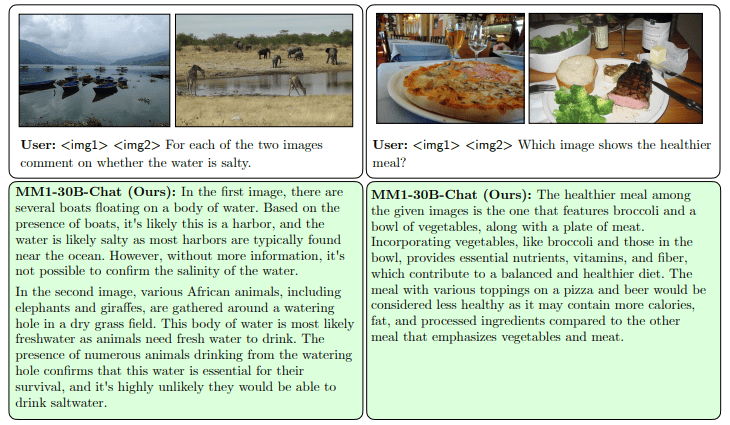
Examples testing MM1’s ability to perceive image aesthetics and compare multiple images:

MM1 on task-oriented scenarios such as operating machines and navigating:

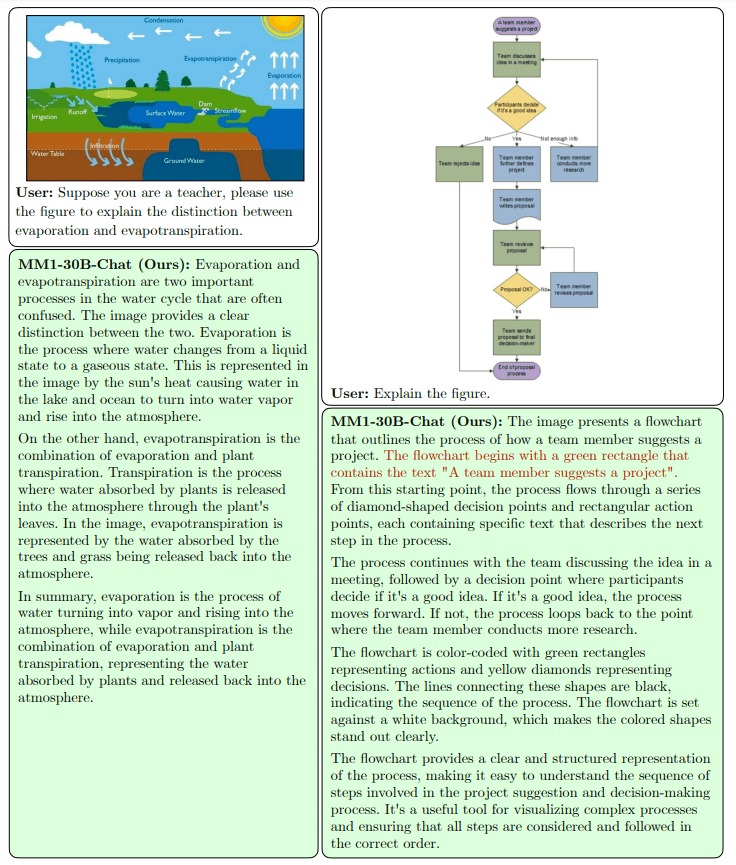
Testing MM1’s ability to extract information from graphics:
It is very soon to say when it will be publicly released, till then, here is a comparison of Gemini 1.5 vs Claude 3 vs GPT-4 to check.
Conclusion
MM1 holds promise as a noteworthy milestone in the advancing field of multimodal AI. By furnishing a robust empirical basis for model design and training, it establishes the framework for forthcoming advancements in the domain. However, it remains to be seen if MM1 can have a life-changing impact!




