



Just days after SIMA’s release, the Google DeepMind team came up with another state-of-the-art technology called VLOGGER. This tool lets you generate controllable lifelike avatar videos from still images. So, how good is VLOGGER and what can developers do with it? Let’s find out!
Highlights:
- Google DeepMind introduces VLOGGER, an AI-generating model that produces lifelike videos of the image subject.
- Based on a diffusion model, its architecture is built on two main components namely a Human to 3D motion model and a novel-based diffusion architecture.
- Comes with several other features including Video Editing and Translation.
What is Google’s VLOGGER?
VLOGGER is an AI method developed by Google for text and audio-driven talking human video production from a single input image of an individual.
This AI model can turn a still image into an animated avatar while preserving the subject’s genuine appearance in each frame of the resulting video. After that, the model processes lip and body movements from an audio file of the speaker to replicate how that person would naturally move if they were speaking the words.
In the official announcement, they have provided details regarding Vlogger’s capabilities and the cutting-edge technology behind its workflow:
We propose VLOGGER, a method for text and audio-driven talking human video generation from a single input image of a person, which builds on the success of recent generative diffusion models.
Enric Corona, Research Scientist at Google
VLOGGER makes it possible to create high-quality, varying-length films with readily configurable high-level human face and body representations. Without external references other than the image and music, this involves generating head motion, facial expression, eye look, blinking, hand movements, and upper body movement.
Recently, we also saw SORA can generate videos from images, a feature quite similar to what VLOGGER does. There is also EMO AI which is competing with SORA.
The Technology Behind VLOGGER
With just one input image and one audio clip, VLOGGER is a unique framework that creates photorealistic films of people conversing and moving. With the use of this technology, a still image can be animated, but it also allows for the creation of head, eye, blink, lip, upper body, and hand gestures.
Vlogger’s technology is based on two main methods. These methods take a departure from the previous traditional approaches as they generate the entire image and not just the face and lips.
They do not depend on face detection and cropping, do not require training for each subject, and take into account a wide range of scenarios like visible torsos or diverse subject identities that are essential to accurately synthesizing humans who communicate.
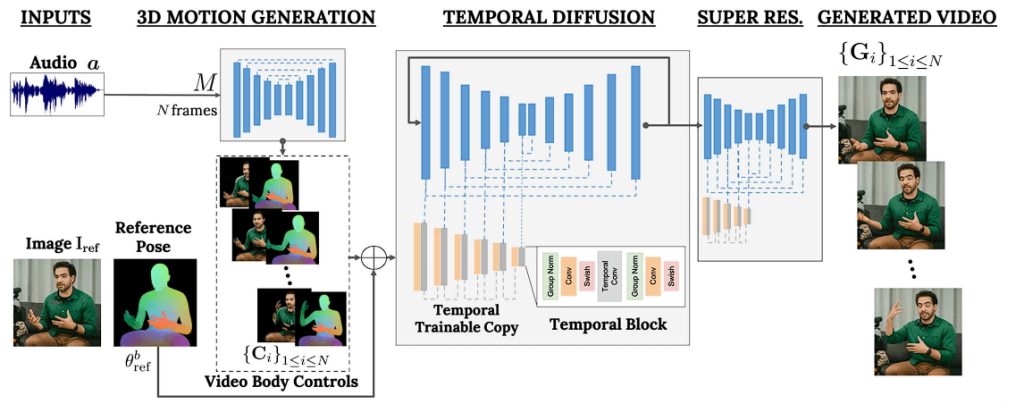
The framework used by VLOGGER models the one-to-many mapping from speech to video using a two-stage pipeline based on stochastic diffusion models. Here we have discussed the methods workflow in-depth:
A Human-to-3D-Motion Model
Using stochastic processes, this component cleverly anticipates facial expressions and body movements depending on the audio input, capturing the complex (one-to-many) link between speech and physical expressions.
It uses the image and audio as input, creates a 3D motion model, and then applies a “temporal diffusion” model to ascertain timings and movement. The audio input is in the form of a waveform that regulates gaze, facial expressions, and position throughout the desired video length to provide intermediate body motion controls.
This is quite an advancement as users can personalize the video generations according to their audio-based inputs which can be anything starting from their voice to any music and much more.
A Novel Diffusion-Based Architecture
The second component is a temporal image-to-image translation model that builds upon big image diffusion models by producing the corresponding frames based on expected body controls. The network furthermore obtains a reference image of an individual in order to condition the process to a specific identification.
By adding temporal and spatial controls to text-to-image models, this architecture guarantees the production of high-quality videos. It offers an extremely detailed control mechanism for the video synthesis process, making it possible to create visually stunning, diversified, and temporally consistent content.
What are its Features?
Although there are several existing image-to-avatar video generation tools available on the market such as Synthesia and Pika Labs, Google’s VLOGGER comes with several unique functionalities across diverse use cases which can be of much benefit to the developer community.
1) Video Diversity
Stochastic in nature, VLOGGER can produce many videos on the same subject or object character. With a great deal of motion and realism, the model produces a wide range of films of the original subject.
We obtained the series of images from VLOGGER’s research paper which shows the video diversity feature in action. As the video progresses, the first row reveals that although the background appears nearly constant, there is a noticeable increase in change in the face, hair, gaze, and body mobility.

Columns 2 through 5 display the variance in pixel colour after 1-4 seconds, respectively, derived from 24 created films, given the subject images and an input speech. The subject displays a wide range of hand poses and facial emotions in just one second (second column), and all of the films have good visual quality.
2) Video Editing
This is one of VLOGGER’s amazing cutting-edge technical features. In this instance, VLOGGER takes a video and modifies the subject’s expression by, for example, shutting their mouth or their eyelids.
By inpainting image elements that ought to change, the diffusion model’s flexibility is utilized to ensure that the video edits remain consistent with the original, unaltered pixels. After the face is edited, an inpainting mask is automatically created using the body coordinates that differ from those in the ground picture.
The first row of the image below shows the input video. The fourth row of the video features the VLOGGER defining various facial expressions, such as changing their mouth (second row), their eyes (third row), or their eyes being open throughout. The body’s shifting portions naturally define the temporal inpainting mask.

3) Video Personalization
This is a recent groundbreaking feature as personalization for subject-driven generation has been thoroughly investigated in the context of diffusion models.
VLOGGER can only synthesize images from a single monocular input image. Although it can create a credible synthesis, it is unable to access areas of the image that are obscured, therefore the final video may not be an accurate fine-grained study of the subject.
Through the process of fine-tuning the diffusion model with additional data, VLOGGER may become more adept at capturing the subject’s identity on a monocular video.
The image below demonstrates how improving the model based on a single-user video allows for more realistic synthesis across a variety of expressions.

4) Video Translation
This is another immaculate feature of VLOGGER that allows you to accurately translate the audio language of the video to any other language by syncing the speaking subject’s facial movements (lip and face areas) consistently with the new audio.
Are there Any Limitations?
One of VLOGGER’s limitations is that even though it can produce motion that looks lifelike, the video cannot always reflect how the subject moves. Fundamentally, it is still a diffusion model, and they are susceptible to odd behaviour.
Second, according to the team, it has trouble in surroundings that are too different or with very big motions. Moreover, it is limited to handling brief videos.
Can you Access VLOGGER?
As of the initial update, VLOGGER is just a research project with a few entertaining sample demos, but if it becomes a product, it has immense potential to transform the field of image-to-video generation.
It is currently just a research idea with few video samples but we can expect it to come up with more such features, narrowing the gap between images and avatars.
Conclusion
VLOGGER is just in its research and development phase, yet it is already offering various unique capabilities compared to several other similar existing tools such as Pika Labs and Synthesia. The world of generative AI keeps impressing us developers day by day, and VLOGGER is just another step in this advancement.




