



After the release of Anthropic’s latest model Claude 3, Generative AI developers can’t help but draw out Claude 3’s comparisons between all the leading AI giants such as Google’s Gemini and OpenAI’s GPT 4. So, we have provided an in-depth comparison between the three models, so that you can decide which one is the best suited tool for you.
Comparing Claude 3, Gemini, and GPT 4
Anthropic has shown with the help of benchmarks across ten different evaluations that Claude 3 beats Gemini and GPT-4 in every one of those aspects. These aspects include undergraduate-level expert knowledge (MMLU), graduate-level expert reasoning (GPQA), basic mathematics (GSM8K), and more.
Coding and Evaluation
We first tested Claude 3 Sonnet, Gemini 1.0 Pro, and GPT 4 based on Coding and Evaluation Performance. We asked the models a similar question “Give the selection sort coding”. These are the results we got:
Claude 3:
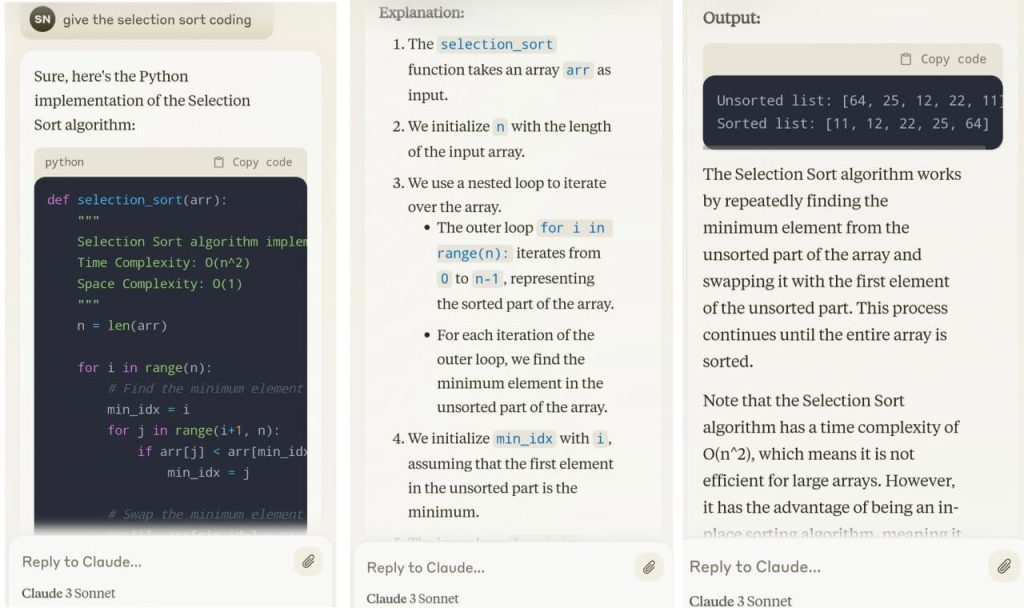
Gemini:
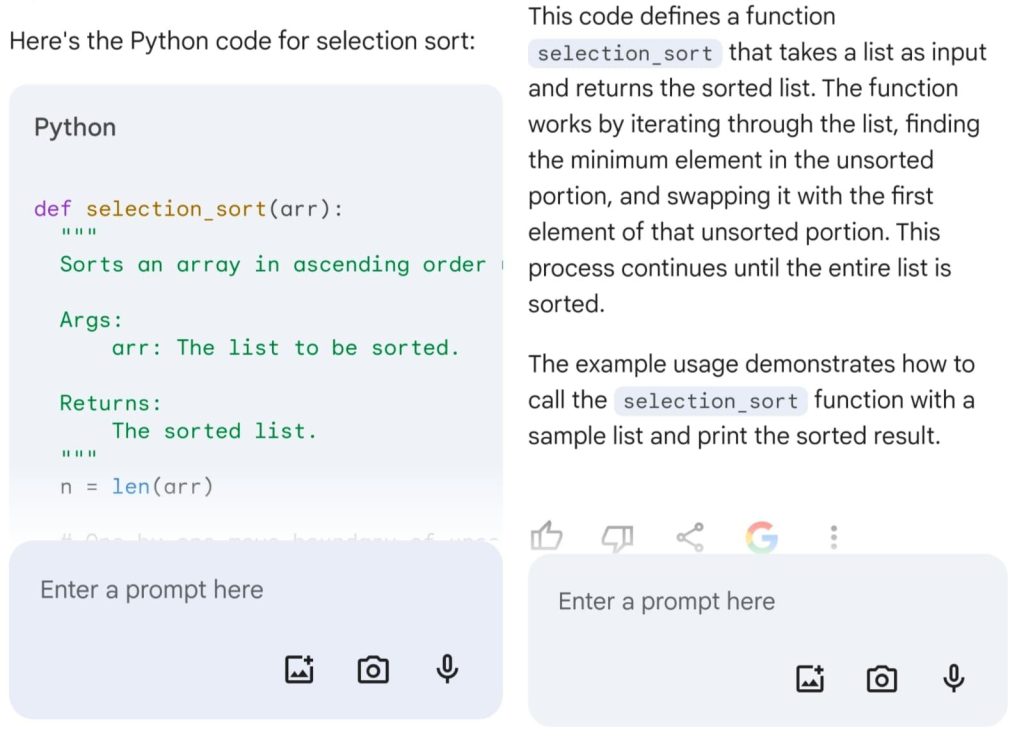
GPT-4:
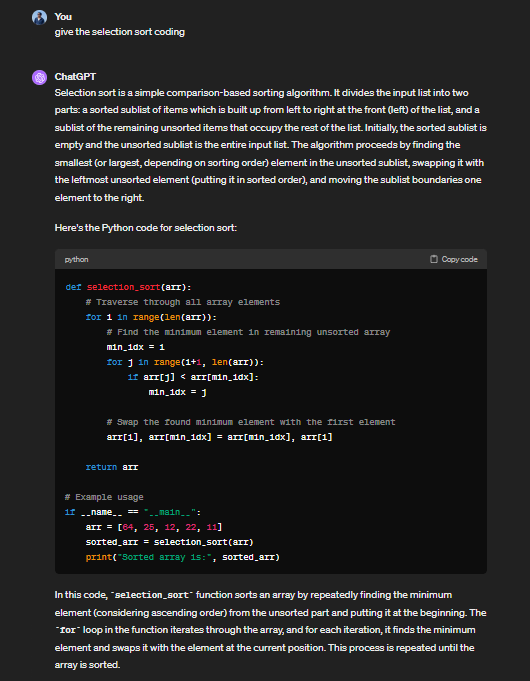
You can see that almost both the models generated the same code snippet including an example usage array in the end.
However, the turning point comes in when we see that Claude 3 proceeds further to provide a detailed explanation of the code and even provides a sample output for selection sort in doing so. Meanwhile, Gemini and GPT-4 just give a brief summarization of the problem without even giving any sample outputs.
On paper, Claude 3’s Opus and Sonnet models show 84.9% and 73% in Code HumanEval metrics which is almost an improvement over GPT-4’s and Gemini 1.0 Pro’s 67% and 67.7% respectively.
Overall, we can conclude that when it comes to creating conversational AI, GPT-4 excels in creating source codes that sound human, engaging in meaningful dialogues, and providing answers to a range of questions.
ChatGPT’s greatest asset is its adaptability to a variety of scenarios, but it falls short of Claude 3 when it comes to vision-related activities or specific benchmarks where Claude 3 does exceptionally well.
When it comes to combining coding and textual understanding, Gemini has been a formidable competitor. Even though it still performs well in visual tasks, Claude 3’s introduction has brought attention to certain areas that need work, particularly in tasks requiring accuracy and a better contextual understanding.
Mathematical Reasoning
By benchmarks, Claude 3’s model shows a vast improvement in Math Problem Solving metrics over both Gemini and GPT-4.
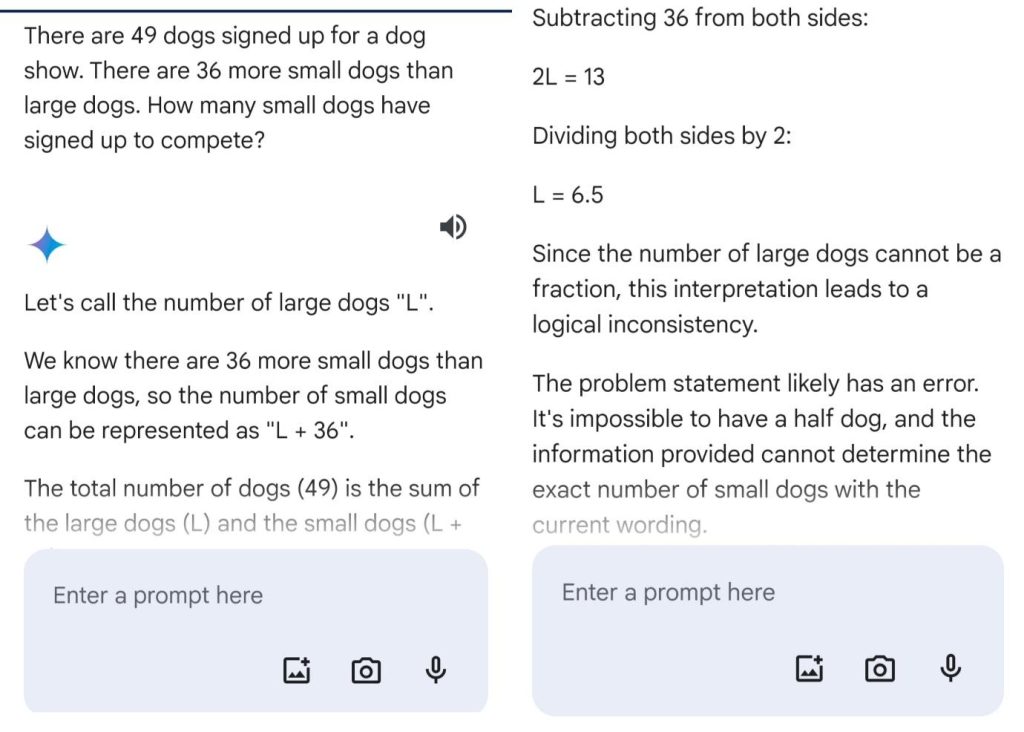
We took to asking a tricky maths question to all three models separately. The question asked separately was “There are 49 dogs signed up for a dog show. There are 36 more small dogs than large dogs. How many small dogs have signed up to compete?”. These are the results we obtained:
Claude 3:
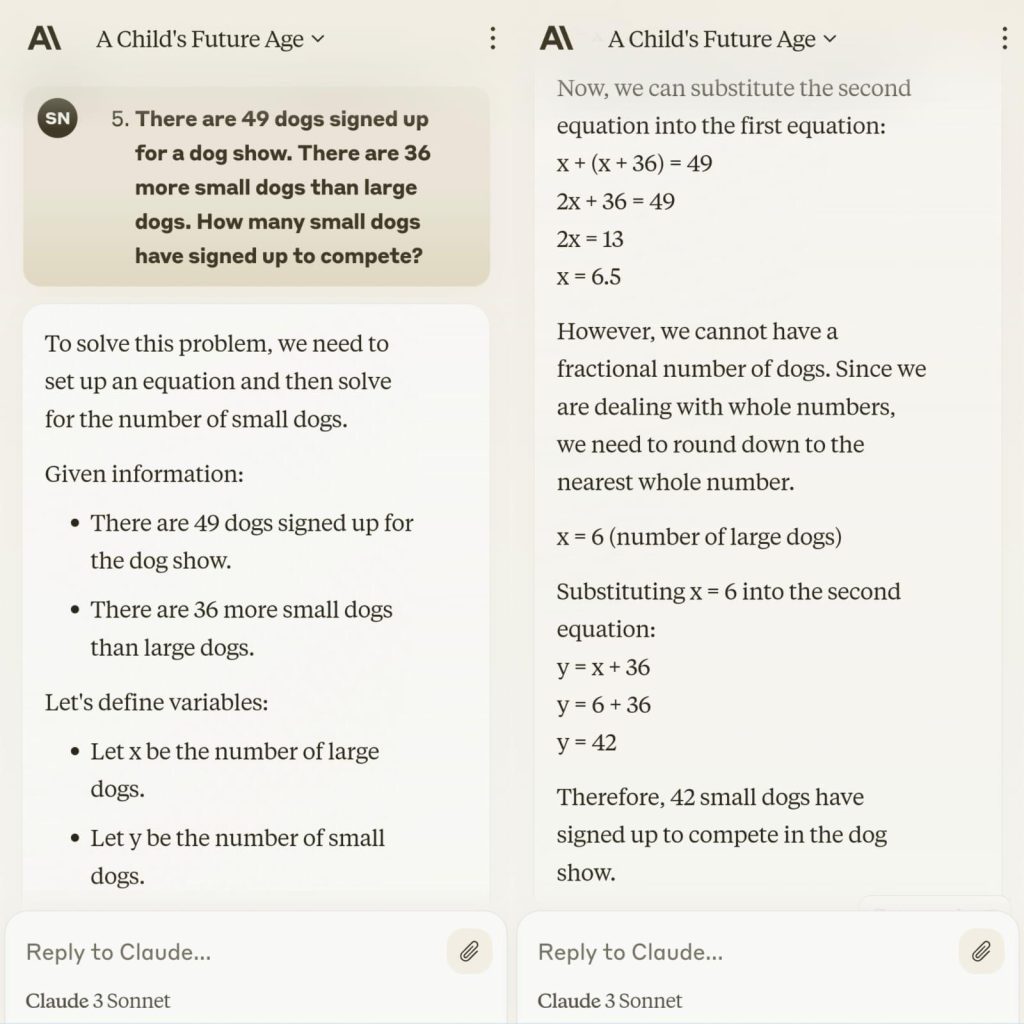
Gemini:
GPT-4:

We were shocked to see that Claude 3’s Sonnet model gave a perfect answer of 42 with a detailed explanation, however, Gemini 1.0 Pro and GPT-4 failed with logical inconsistencies in their solutions.
Gemini couldn’t even reach an answer and GPT-4 got an incorrect whole number answer of 42.5. Claude 3 showed its complex mathematical understanding by rounding up the whole number but GPT-4 keeps on making calculations and makes the solution lengthy.
Thus, we can conclude that as developers if you deal with very complex mathematical reasoning problems then you must stick to Claude 3’s Opus and Sonnet Models. They also show vast improvement in Grad School Math and Multilingual Math Problem Metrics.
Vision Capabilities
We took to seeing Claude 3’s strong vision capabilities which were on par with other models as shown in their blog.
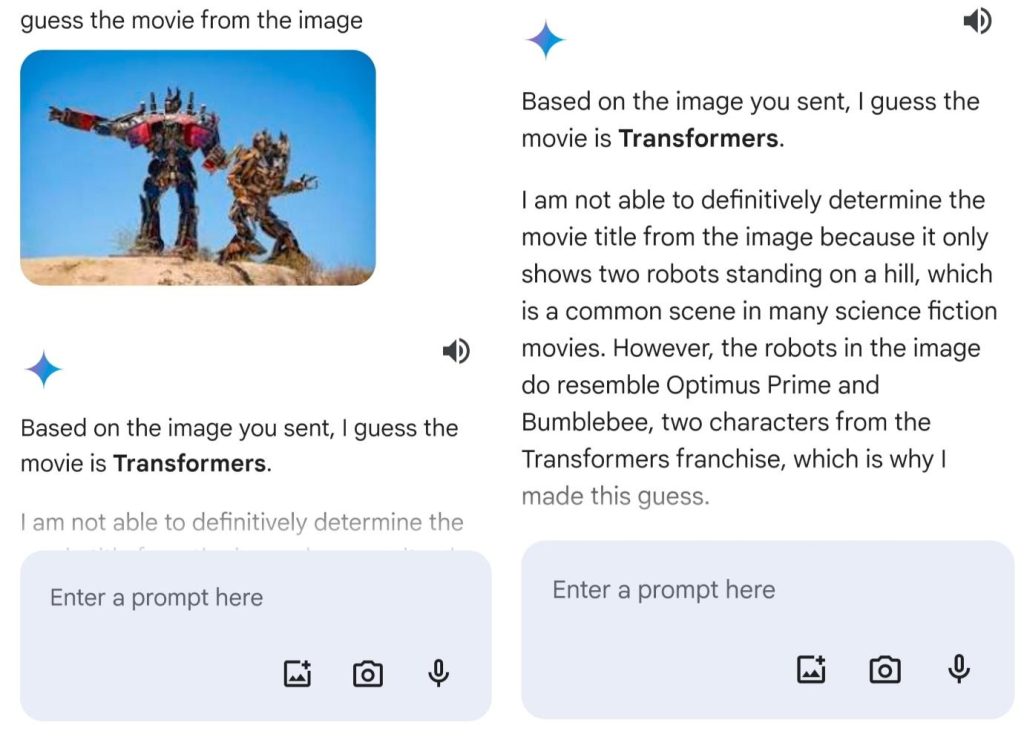
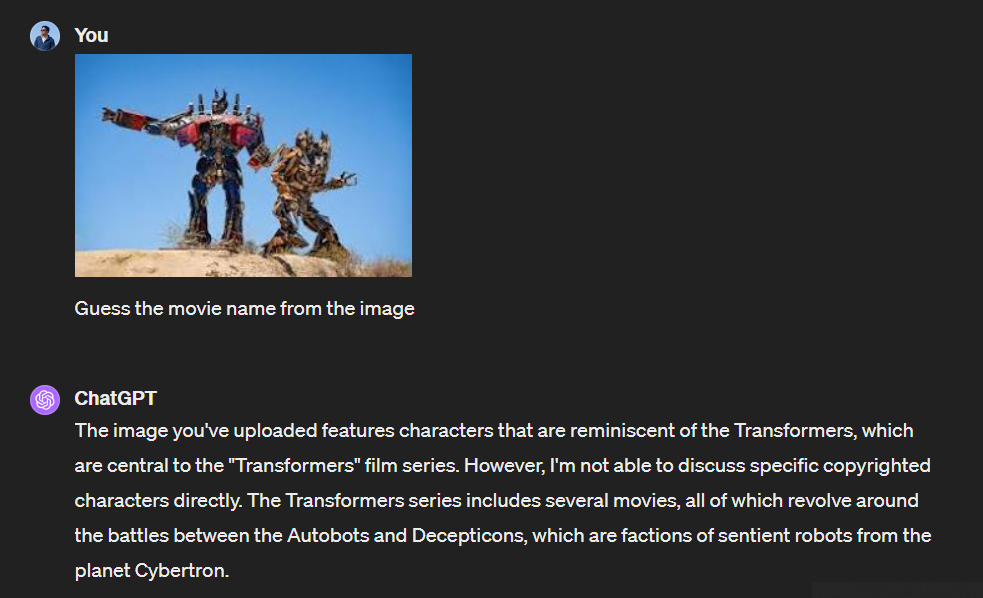
So, we took to asking all Gemini 1.0 Pro, Claude 3 Sonnet, and GPT-4, “Guess the movie name from the image”.
At first, we gave an input image from the Transformers franchise. All three got the movie name right but they had different sorts of explanations on how they managed to come up with the name. GPT-4 showed some hesitation in discussing the Transformers characters.
Claude 3:

Gemini:
GPT-4:
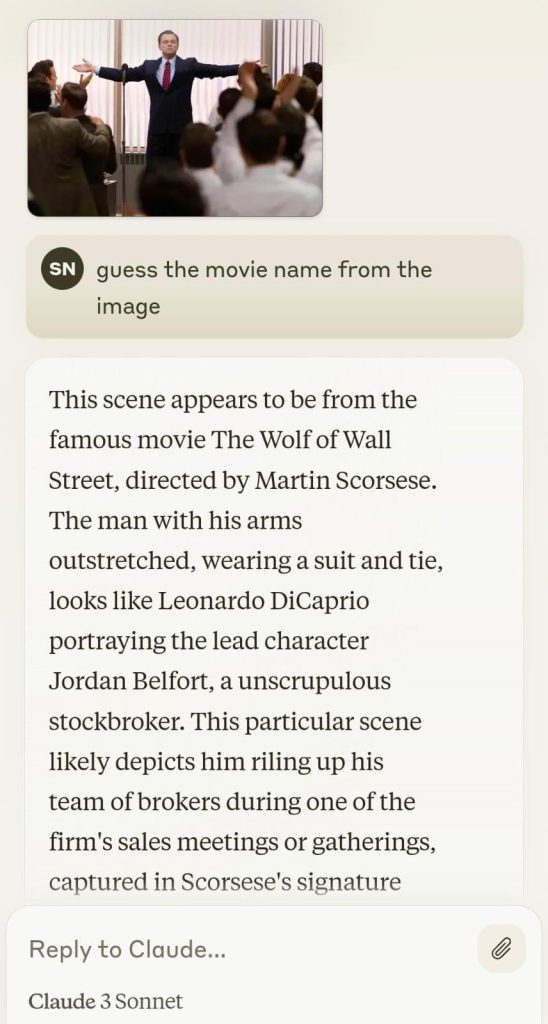
We continued further by providing an image from the popular movie “The Wolf of Wall Street”. Claude 3 and GPT successfully identified the movie from the image but Gemini refused to provide any response based on an image containing images of famous personas. Maybe this can be attributed to Google’s policies on ethics and safety regarding image generation.
Claude 3:
Gemini:
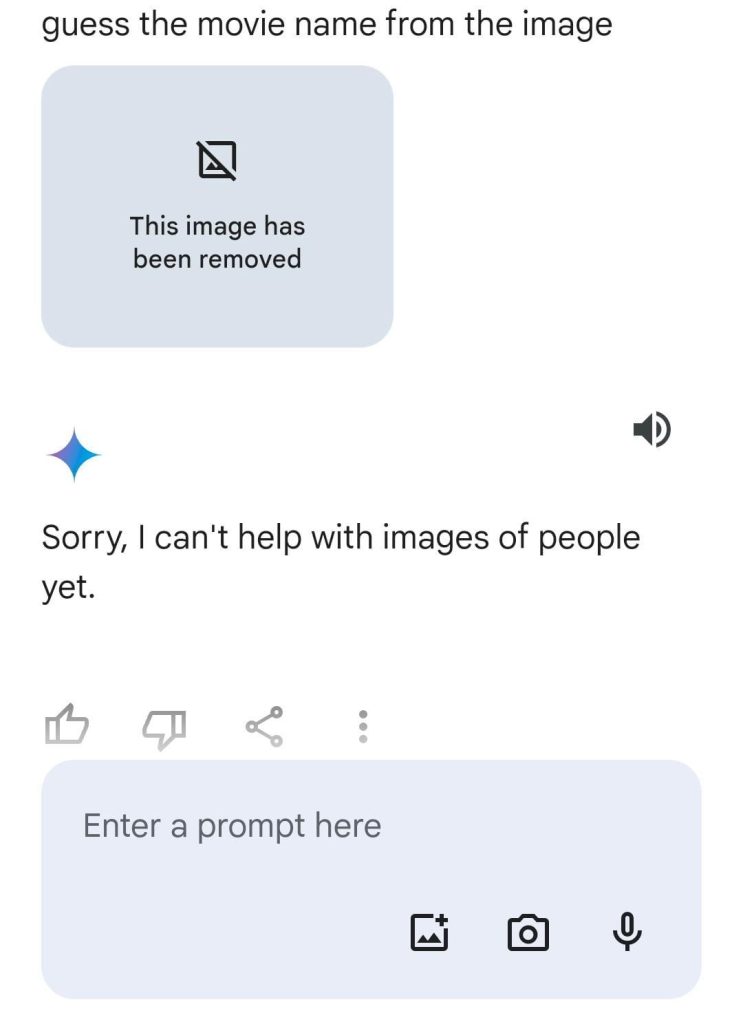
GPT-4:
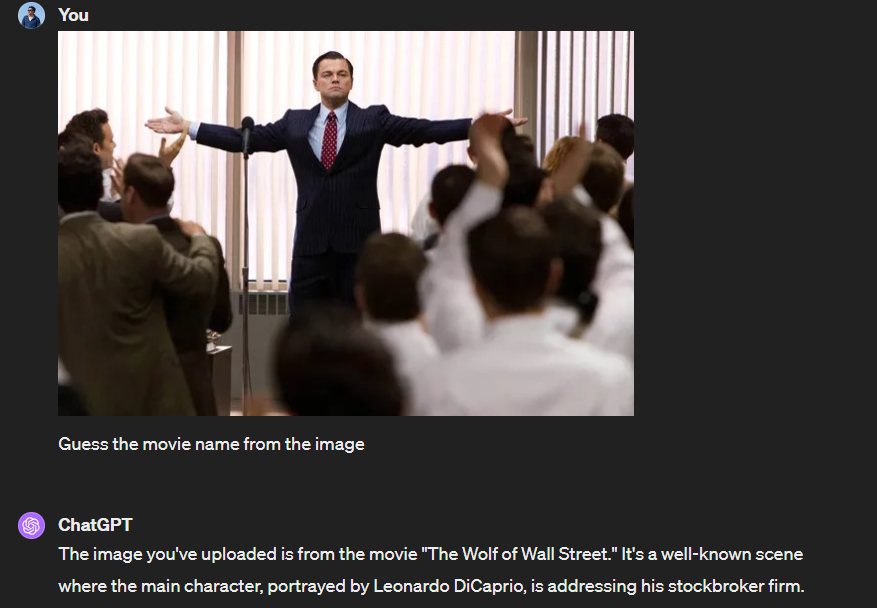
Overall, in this aspect, it’s hard to pick a winner because all three of them gave almost perfect responses. But if developers want more flexibility and fewer refusals to harmless content questions, our suggestion is to try out Claude 3. Also, Claude 3, had faster response times to our image-based questions.
General and Common Knowledge
Claude 3 Benchmarks show a slight improvement in Knowledge Q&A and Common Knowledge metrics over both Gemini and GPT-4. To test this, we asked a basic question to all three models: “Why does the sun rise in the East”?.
To our surprise, all three responses were correct in their explanation however the differences were found in the reasoning and logical conclusions derived from the answers.
Claude 3:
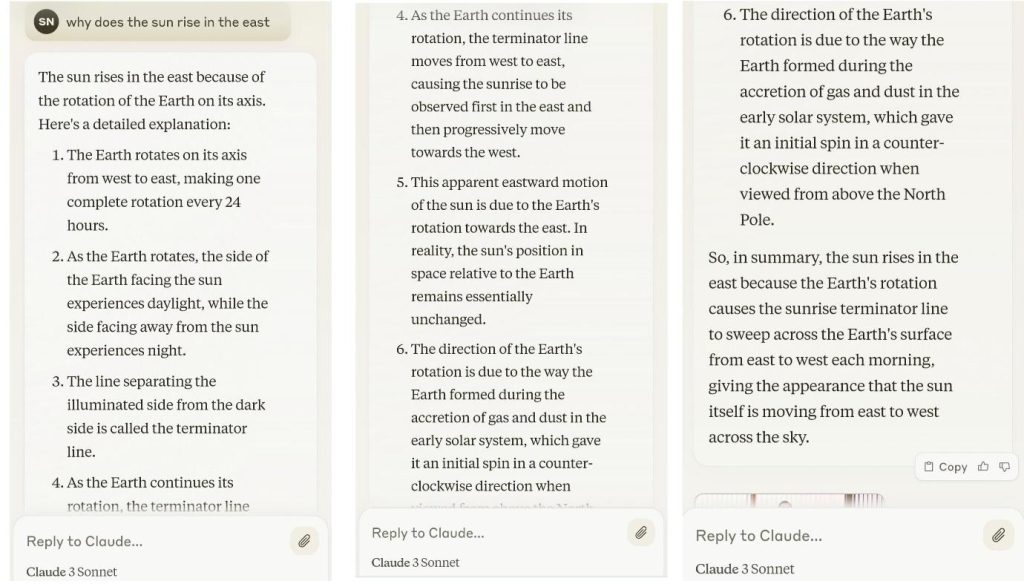
Gemini:
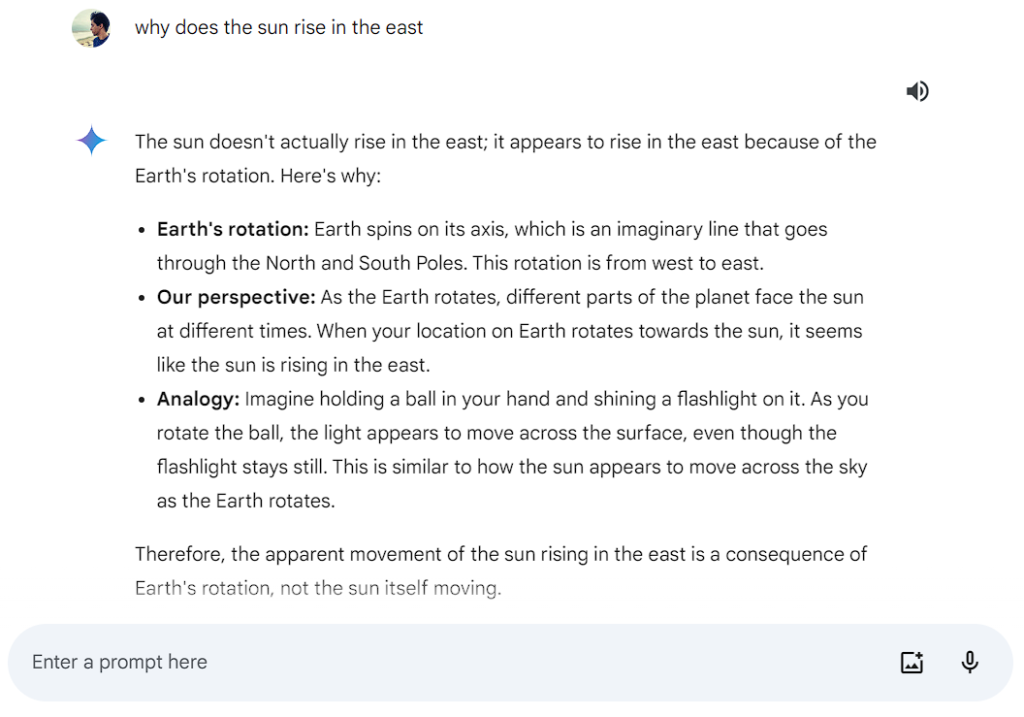
GPT-4:
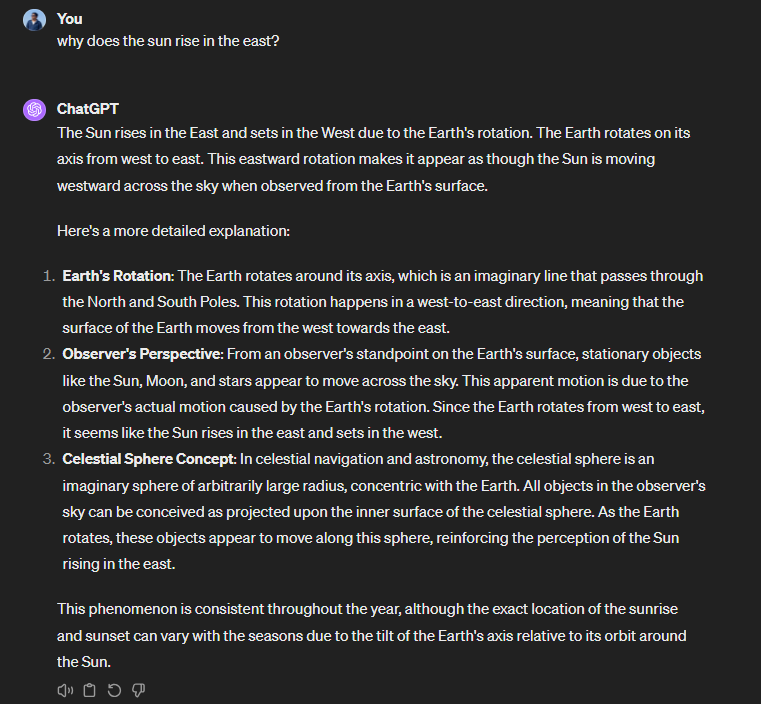
As you can see Gemini 1.0 Pro gives a correct answer but makes use of general referential aspects to explain their points. Claude 3 Sonnet and GPT-4 stick more to the scientific norm and give a proper explanation of the phenomenon in detail. It even makes use of scientific terms.
Here it is hard to conclude a specific winner as well, but still, we have chosen Claude 3 and GPT-4 as the better alternative as it gives a more scientific knowledge representation which is a symbol of its high general and common knowledge capabilities.
So, if you are looking for basic answers with general explanations stick to Gemini, however, Claude 3 and GPT-4 may provide you with more detailed intricate knowledge of science and reasoning.
Who is the Winner?
Claude 3, which has been praised for being a major improvement over its predecessors and rivals, stands out for its strengths in optical character recognition (OCR), sophisticated query interpretation, and enhanced benchmark performance.
Based on our results and conclusions we will say that Claude 3 is the justified winner as it takes the big lead in two important aspects of Coding Evaluation and Mathematical Reasoning.
However, it’s hard to give an absolute answer to overall which tool is suited for developers as it depends on your sole use and preferences. On paper, Claude 3 has improvements in vision capabilities such as summarizing and image processing including text extraction over GPT-4 but slightly falls behind Gemini in some aspects.
ChatGPT (GPT-4) provides an extensive knowledge base and strong conversational skills. It might not be as good as Claude 3 at OCR jobs, but it’s still a useful tool for a variety of text-based tasks like writing, summarising, and answering questions.
Because of its conversational style, GPT-4 is very flexible and easy to use, but it occasionally performs less well than the most recent version of Claude 3 in some technical benchmarks.
Both the unreleased Gemini 1.5 and the Gemini 1.0 Ultra demonstrate good general AI skills and performance in visual tasks. However, the release of Claude 3 has limited Gemini’s potential, especially when it comes to OCR and context-specific searches. Even while Gemini 1.5 Pro outperforms its predecessor, it still has trouble matching Claude 3’s sophisticated reasoning and OCR skills.
Conclusion
We must not forget that all three AI giants namely Claude 3, Gemini, and GPT-4 are significant advancements in the world of Generative AI. All three tools come with significant capabilities across diverse functionalities and we must not overlook any of them due to any limitations. At some point as developers, we will need all three of them.




